今回S3にある、圧縮された配列でできているJSONファイルをembulkでBigQueryにシンクしてみました。配列という稀なケースでしたが、プラグインの公式をちゃんと嫁ばできる!
■test.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ "Id": "xxxxx", "ID_c": "1111", "Name": "あだちん工業", "MyNumberBiz_c": "123456789", "date_c": "2018-06-22 06:44:04", "LastModifiedDate": "2019-05-19 11:10:31", "Jigsaw": null, "Fax": "****" }, { "Id": "xxxxxxxxx", "ID_c": "1920", "Name": "アダチン", "MyNumberBiz_c": "1234567890333", "date_c": "2018-06-22 08:29:51", "LastModifiedDate": "2019-05-19 10:23:17" } ] |
■hiroyuki-sato/embulk-parser-jsonpath
https://github.com/hiroyuki-sato/embulk-parser-jsonpath
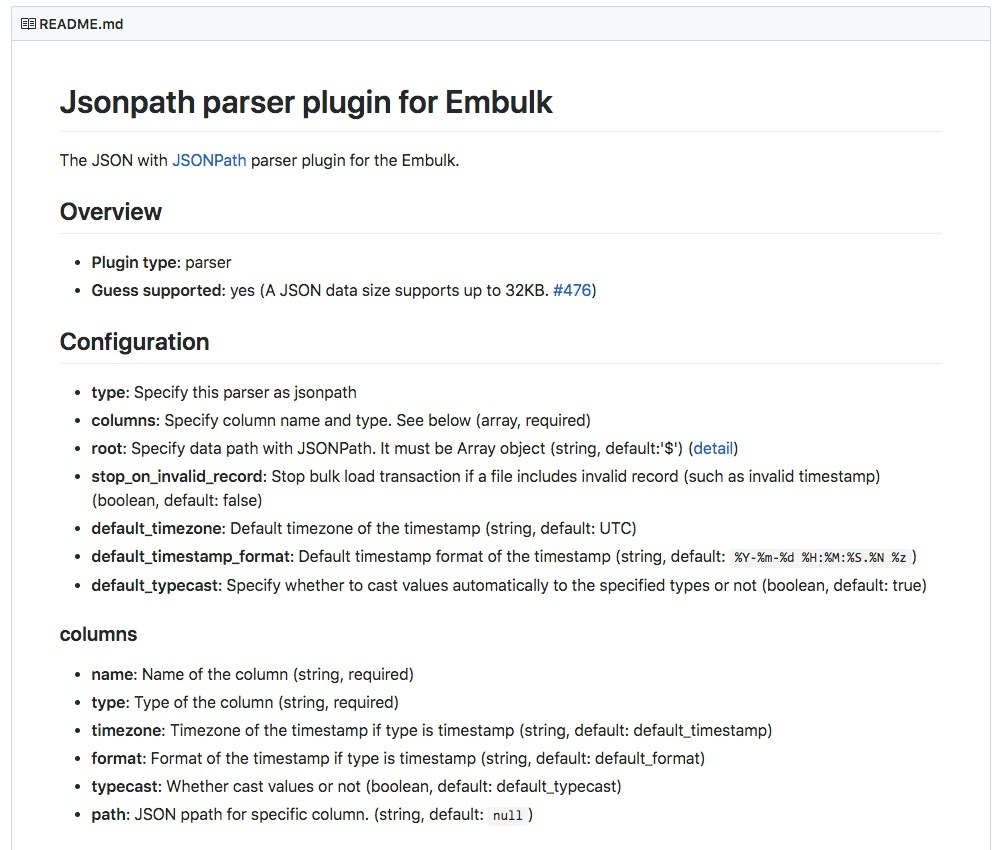
type: jsonpath にするだけでOK
※ちなみにembulk-input-s3プラグインはインストールされている前提です。
https://github.com/embulk/embulk-input-s3
- プラグインインストール
|
1 2 3 4 5 6 7 8 |
$ gem search -r embulk-parser-jsonpath *** REMOTE GEMS *** embulk-parser-jsonpath (0.3.1) $ vim digdag/vendor/Gemfile gem 'embulk-parser-jsonpath' #追加 |
- 反映
|
1 2 3 4 5 |
$ embulk bundle $ grep embulk-parser-jsonpath Gemfile.lock embulk-parser-jsonpath (0.3.1) embulk-parser-jsonpath |
■embulk/digdag
- test.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
in: type: s3 path_prefix: db/test/{{ env.s3_target_date }}/test.json bucket: {{ env.EMBULK_INPUT_S3_BUCKET }} access_key_id: {{ env.AWS_ACCESS_KEY }} secret_access_key: {{ env.AWS_SECRET_KEY }} parser: type: jsonpath charset: UTF-8 newline: CRLF columns: - {name: Id, type: string} - {name: ID_c, type: string} - {name: Name, type: string} - {name: MyNumberBiz_c, type: string} ~省略~ out: type: bigquery mode: replace auth_method: json_key json_keyfile: /opt/redash/digdag/s3_to_bigquery/config/bq.key {% if env.EMBULK_ENV == 'production' %} {% include 'db/prod_bigquery' %} {% else %} {% include 'db/pre_bigquery' %} {% endif %} auto_create_dataset: true auto_create_table: true dataset: adachin_db table: test schema_file: /opt/redash/digdag/s3_to_bigquery/embulk/db/test.json open_timeout_sec: 300 send_timeout_sec: 300 read_timeout_sec: 300 auto_create_gcs_bucket: false gcs_bucket: {{ env.EMBULK_OUTPUT_GCS_BUCKET }} compression: GZIP source_format: NEWLINE_DELIMITED_JSON default_timezone: Asia/Tokyo default_timestamp_format: '%Y-%m-%d %H:%M:%S' |
- embulk/db/_pre_bigquery.yml.liquid
|
1 2 |
# project: pre-adachin |
- test.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[ { "name": "ID", "type": "STRING" }, { "name": "ID_c", "type": "INT64" }, { "name": "Name", "type": "STRING" }, { "name": "MyNumberBiz_c", "type": "STRING" }, ~省略~ ] |
- test.dig
|
1 2 3 4 5 6 7 8 9 |
_export: s3_target_date: ${moment(session_date).subtract(1,'days').format('YYYY-MM-DD')} bq_target_date: ${moment(session_date).subtract(1,'days').format('YYYYMMDD')} _error: sh>: export $(cat config/env | xargs) && /opt/redash/digdag/post_slack.sh "[${session_time}][${session_id}] DigDag Fail test" +load: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/test.yml.liquid |
- 実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
$ digdag run test.dig --rerun 2019-05-26 22:40:19 +0900: Digdag v0.9.19 2019-05-26 22:40:21 +0900 [WARN] (main): Reusing the last session time 2019-05-24T00:00:00+00:00. 2019-05-26 22:40:21 +0900 [INFO] (main): Using session /opt/redash/digdag/s3_to_bigquery/.digdag/status/20190524T000000+0000. 2019-05-26 22:40:21 +0900 [INFO] (main): Starting a new session project id=1 workflow name=account session_time=2019-05-24T00:00:00+00:00 2019-05-26 22:40:23 +0900 [INFO] (0016@[0:default]+test+load): sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/test.yml.liquid 2019-05-26 22:40:23.447 +0900: Embulk v0.8.35 2019-05-26 22:40:34.663 +0900 [INFO] (0001:transaction): Loaded plugin embulk-input-s3 (0.2.14) 2019-05-26 22:40:34.787 +0900 [INFO] (0001:transaction): Loaded plugin embulk-parser-jsonpath (0.3.1) 2019-05-26 22:40:36.425 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=4 / output tasks 2 = input tasks 1 * 2 2019-05-26 22:40:36.437 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2019-05-26 22:40:36.502 +0900 [INFO] (0017:task-0000): JSONPath = $ 1234567890111,あだちん株式会社,1925, 1234567890222,あだちん工業,1926, 1234567890333,アダチン,1928, 2019-05-26 22:40:36.972 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0} 2019-05-26 22:40:36.978 +0900 [INFO] (main): Committed. 2019-05-26 22:40:36.978 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"db/adachin/test/dt=2019-05-23/test_20190523.log_0.gz"},"out":{}} Success. Task state is saved at /opt/redash/digdag/s3_to_bigquery/.digdag/status/20190524T000000+0000 directory. * Use --session <daily | hourly | "yyyy-MM-dd[ HH:mm:ss]"> to not reuse the last session time. * Use --rerun, --start +NAME, or --goal +NAME argument to rerun skipped tasks. |
今回outの部分をtype: stdoutにして標準出力できるか確認してみましたが、ちゃんと出力されてますね。
- BigQuery
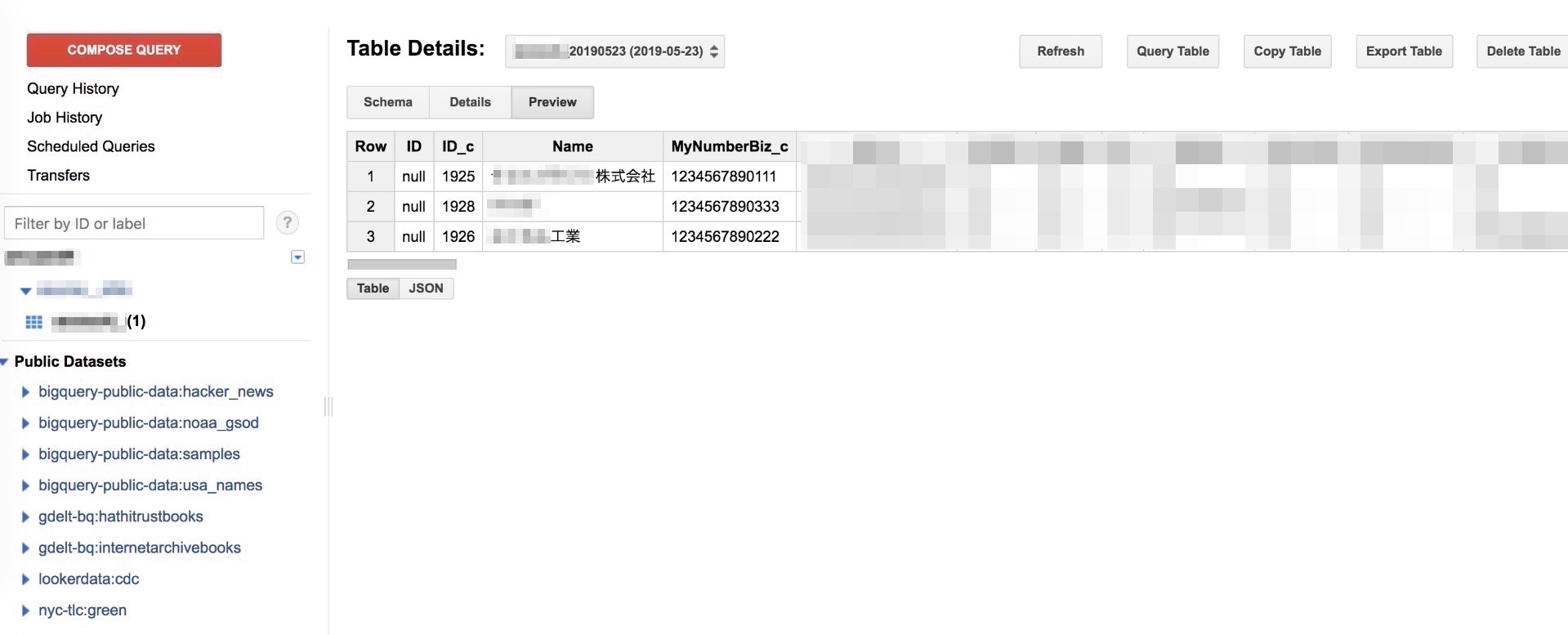
■まとめ
しかしこのプラグイン配列だろうがなんだろうが、様々な形式に対応しているので万能ですな。
そしてこのプラグインを作った@hiroysatoさんからリプ!
ご紹介ありがとうございます。今(v0.9.16以降)は組み込みjsonでも類似の機能が使えるのでこちらもいいですよ。https://t.co/9R33kzVqxEhttps://t.co/41X7SAtduh (__experimental_xxを外してください)
— Hiroyuki Sato (@hiroysato) May 27, 2019


0件のコメント