digdagわかりません
— adachin?SRE (@adachin0817) August 2, 2019
Google Analytics(GA)のデータをdigdag(embulk)でBigQueryにシンクしているのですが、 view_id をもう一つ追加してほしいと依頼がありまして、(以下実装に関してはgodgarden氏の以下を参考に) digdagの for_each を使えば設定ファイル新しく作らなくて済むし、管理も楽だよとのことなのですが、1週間くらいドハマリしたのでブログします。
https://qiita.com/godgarden/items/6309f842aeb0eb29a168

- for_each>: Repeat tasks for values
https://docs.digdag.io/operators/for_each.html
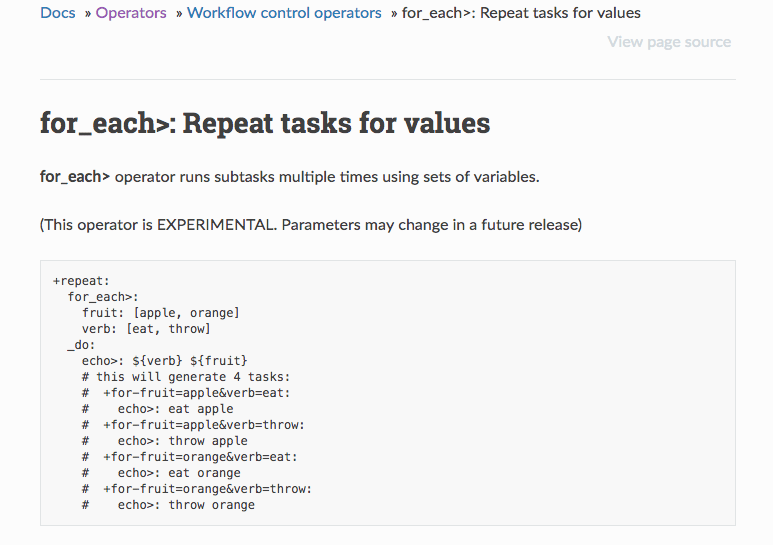
■embulk/digdag
- embulk/ga_test.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
in: type: google_analytics json_key_content: | { "type": "service_account", "project_id": "{{ env.project_id }}", "private_key_id": "{{ env.private_key_id }}", "private_key": "{{ env.private_key }}", "client_email": "{{ env.client_email }}", "client_id": "{{ env.client_id }}", "auth_uri": "https://accounts.google.com/o/oauth2/auth", "token_uri": "https://accounts.google.com/o/oauth2/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "{{ env.client_x509_cert_url }}" } view_id: {{ env.view_id }} time_series: "ga:date" # https://developers.google.com/analytics/devguides/reporting/core/dimsmets dimensions: - "ga:eventCategory" - "ga:eventAction" - "ga:eventLabel" metrics: - "ga:totalEvents" default_timezone: 'Asia/Tokyo' start_date: {{ env.ga_target_date }} end_date: {{ env.ga_target_date }} out: type: bigquery mode: append auth_method: json_key json_keyfile: /digdag/ga_to_bigquery/config/bq.key {% if env.EMBULK_ENV == 'production' %} {% include 'db/prod_bigquery' %} {% else %} {% include 'db/pre_bigquery' %} {% endif %} auto_create_dataset: true auto_create_table: true dataset: ga table: content_event_{{ env.bq_target_date }} open_timeout_sec: 300 send_timeout_sec: 300 read_timeout_sec: 300 auto_create_gcs_bucket: false gcs_bucket: {{ env.EMBULK_OUTPUT_GCS_BUCKET }} compression: GZIP source_format: CSV default_timezone: "Asia/Tokyo" default_timestamp_format: '%Y-%m-%d %H:%M:%S' |
17行目がID番号を入れる部分なので変数化します。 view_id: {{ env.view_id }}
あとはrun.digの中で for_each を作ればOKなのですが、以下のようにすると良き!
34行目の mode: append にしている理由としては次の実行で上書きを防ぐように追記にしてます。(1つのdataset)
一週間くらいハマってやる気を失いましたが解決してよかったあざます!
って書き方がムズイ!digdagとembulkで変数を使ってfor_eachで実行する方法 https://t.co/RZm4JwzlMq
— adachin?SRE (@adachin0817) August 6, 2019
- run.dig
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
timezone: Asia/Tokyo schedule: daily>: 03:00:00 _retry: 6 _export: project_id: ${settings.gcp.project_id} private_key_id: ${settings.gcp.private_key_id} private_key: ${settings.gcp.private_key} client_email: ${settings.gcp.client_email} client_id: ${settings.gcp.client_id} client_x509_cert_url: ${settings.gcp.client_x509_cert_url} ga_target_date: ${moment(session_date).subtract(2,'days').format('YYYY-MM-DD')} bq_target_date: ${moment(session_date).subtract(2,'days').format('YYYYMMDD')} bq: 'sudo -u adachin /home/adachin/google-cloud-sdk/bin/bq' settings: !include : config/settings.dig _error: sh>: /digdag/post_slack.sh "[${session_time}][${session_id}] DigDag Fail ga_test" +rm_table: sh>: ./rm_table_if_exists.sh +repeat: for_each>: view_id: [xxxxxx, xxxxxxxxxx] _do: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/ga_test.yml.liquid +bq_copy: sh>: ${bq} cp -f view_ga.test_${bq_target_date} view_ga.test_${bq_target_date} |
- rm_table_if_exists.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#!/bin/bash DATE=$(date +%Y%m%d -d '2 days ago') for i in source warehouse; do bq show ${i}__ga.test_${DATE} if [ $? -eq 0 ]; then bq rm -f ${i}__ga.test_${DATE} fi done |
ちなみに上記のシェルスクリプトですが、digdagを事前に実行すると、テーブルが存在しないとretryされてしまうので、成功したデータが重複して追記されてしまいます。そこでテーブルの存在チェックをして、あれば削除からの入れ直しています。むしろdigdagでif文書けばいいと思うのですが、まったくといってもうまくいかなかった….
30行目での view_id: [xxxxxx, xxxxxxxxxx] は配列でID番号を指定すればOKで、viewにはbqコマンドの -f で強制上書きをしています。
■まとめ
しかし for_each 便利!!!


0件のコメント