急にRedashからSQLを叩くと….まったく反応しない事象が発生しました。(お初)
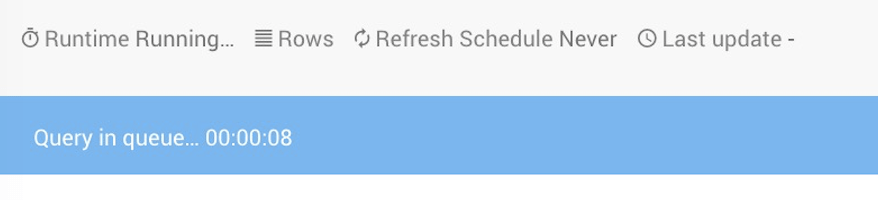
どうやらredashが内部で使用しているジョブキュー(celery)がCPU100%張り付いてキューが詰まって、
それ以降に投げたクエリが応答しなくらしく、OSS側のバグ???(不明)
とのことなので、今回対象方法をブログしやす。
■ReDash keeps queuing up queries #1605
https://github.com/getredash/redash/issues/1605
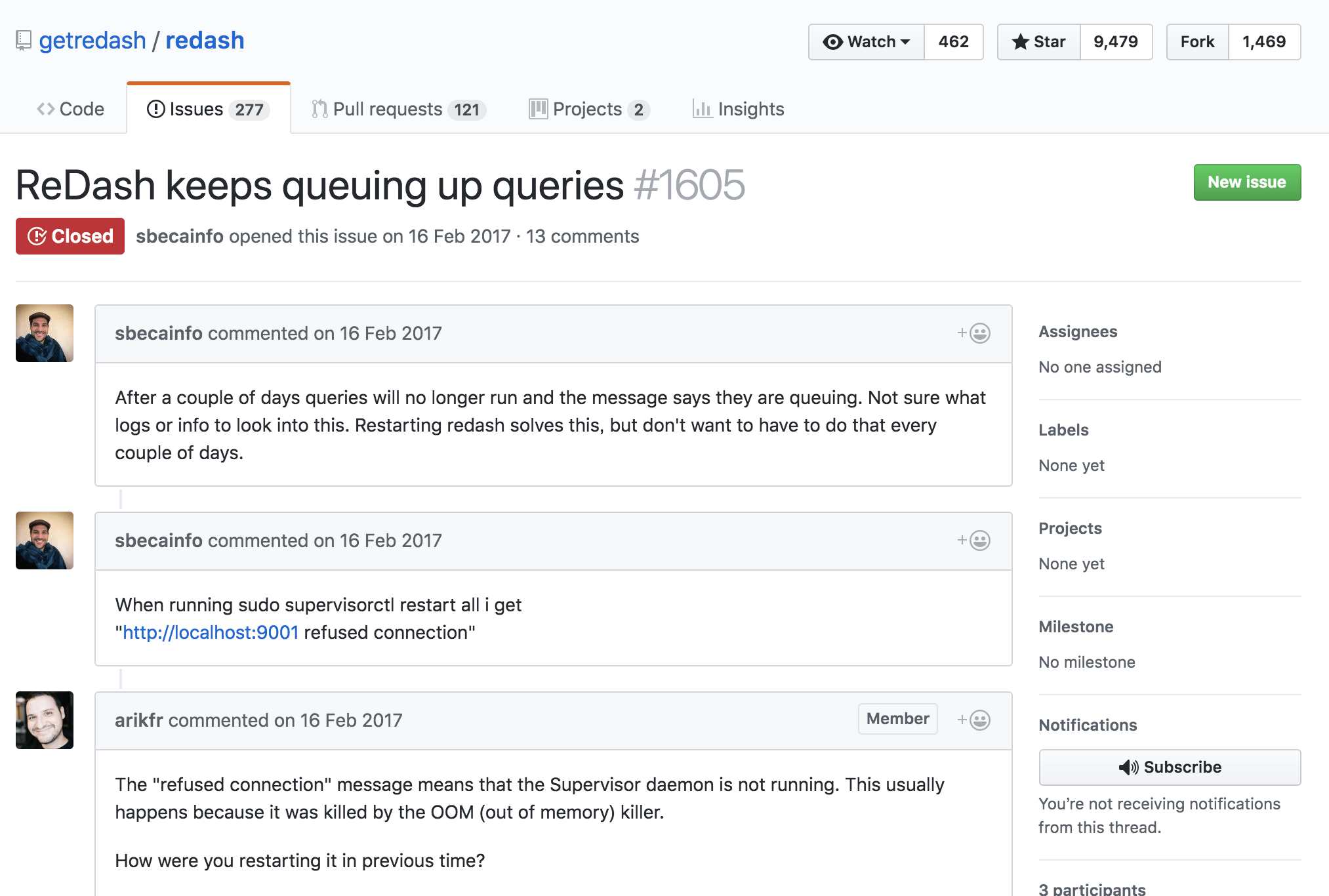
調べてみるとこんなIssueを発見。Redash開発者で有名なArik Fraimovichさんによると、

did you configure Celery with maxtasksperchild?
maxtasksperchild defines after how many tasks the Celery process will kill the worker and start a new one. This helps with returning memory to the system, as otherwise Python won’t return claimed memory. I think there is a way to set max used memory setting for Celery, but never tried it and not sure I trust it.
「maxtasksperchildでCeleryチューニングちゃんと設定してんの?maxtasksperchildは、Celeryプロセスが勝手に殺して新しい作業を開始するタスクの数を定義するんやで。そうしないと、Pythonは要求されたメモリを返さないで。 ちなみに試したことはないし、知らんで。」
と、試したことないんかーーーいとツッコミどころ満載ですが、
どうやらsupervisordの設定ファイルに以下がデフォルトで設定されているので、
–max-memory-per-childも合わせてチューニングすると良いみたい。
|
1 |
--maxtasksperchild=10 #デフォルト |
■早急な対応
・htop打ち込む
|
1 2 |
15137 redash 20 0 316384 110344 10004 R 100.0 0.7 8426:30 [celeryd: celer 3340 redash 20 0 316944 111016 10004 R 100.0 0.7 3799:56 [celeryd: celer |
・redashプロセスを強制kill
|
1 |
$ sudo kill -9 15137 |
これでもだめならもう一個もkillする。
・htopコマンドで確認
CPUが100%になっていなければOK。
■まとめ
とブログ書いていたら前任者のパイセンが直してくれたそうで!?
v4にバージョンアップすれば良さそう!?→あんま関係ない
一定間隔以上、プロセスが張り付いていたら強制killとか…
ここらへんMackerelで対応できそうな気がする。いやmonitか!
ちょいとチューニング試してみやす!!!


0件のコメント