さて、お久しぶりのRedash系ブログでございます。今まではEC2上にDockerをインストールして、docker-composeでRedashのコンテナらを起動して、構築の手間等省けることができました。しかしながら運用上、重たいクエリなど誤って実行してしまうと、サーバーのCPUやロードアベレージが高くなり、結局は再起動するといった手間がかかります。そこで今回EC2(Docker)からECS/Fargateに移行する際注意することをまとめてみたいと思います。ここらへんの検証は同僚の@kata_dev氏が試してくれたのでthanks!!
ECS/Fargateでの構成
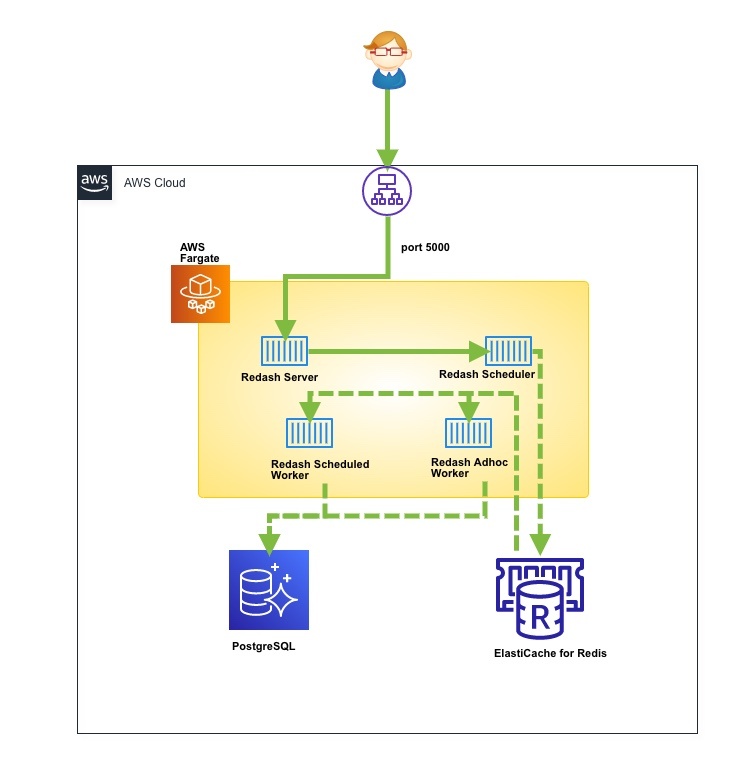
- Redash Server
いつも見てるWebUI ターゲットグループのportは5000 - Redash Scheduler
JobをRedisにキューイング - Redash Scheduled Worker
スケジューリングされたクエリを処理 - Redash Adhoc Worker
都度実行されるクエリを処理
Redashの各コンテナは細かく見ると4つほどあります。(構成図がわかりにくくてすんません)上記でEC2の時に重いクエリでサーバー再起動しなければならない根本的な原因はWorkerが重いからなのです。なので、Workerのスペックを調整して、オートスケールできればサービスが停止することはありません。ここがEC2ではできないECS/Fargateのメリットとなります。EC2の場合は各役割ごとにコンテナを動かすなんでできないですからね。EC2上のDockerと構成は同様ですが、改めて構成図を書いてみるとFargateの場合、中々ややこしい….!!
Terraform
- elasticache.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
resource "aws_elasticache_subnet_group" "redash_redis" { name = "redash-redis-subnet-group" description = "redash-redis-subnet-group" subnet_ids = [ aws_subnet.hoge-elasticache-1a.id, aws_subnet.hoge-elasticache-1c.id, aws_subnet.hoge-elasticache-1d.id ] } resource "aws_elasticache_cluster" "redash_redis" { cluster_id = "redash-redis" engine = "redis" node_type = var.redash_redis_node_type num_cache_nodes = var.redash_redis_num_cache_nodes parameter_group_name = "default.redis5.0" engine_version = "5.0.6" port = 6379 subnet_group_name = aws_elasticache_subnet_group.redash_redis.id security_group_ids = [aws_security_group.redash_redis.id] } |
RedashのRedisのバージョンは5系が推奨されています。6系でも動作するか後ほど確認してみたいと思います。 num_cache_nodes は一つで十分そうですね。
- security-group.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
## security-group (redash_redis) resource "aws_security_group" "redash_redis" { name = "redash-redis" description = "redash-redis" vpc_id = aws_vpc.hoge_vpc.id ingress { from_port = 6379 to_port = 6379 protocol = "tcp" security_groups = [aws_security_group.redash.id] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "redash-redis" } } ## security-group (redash) resource "aws_security_group" "redash" { name = "Redash" description = "Redash" vpc_id = aws_vpc.hoge_vpc.id ingress { from_port = 5000 to_port = 5000 protocol = "tcp" security_groups = [aws_security_group.hoge_alb.id] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "Redash" } } |
- elb_targetgroups.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
resource "aws_lb_target_group" "redash_fargate" { name = "redash-fargate" port = 80 protocol = "HTTP" vpc_id = aws_vpc.hoge_vpc.id target_type = "ip" deregistration_delay = "10" health_check { protocol = "HTTP" path = "/ping" port = 5000 healthy_threshold = 5 unhealthy_threshold = 3 timeout = 5 interval = 30 matcher = 200 } } |
ターゲットグループのヘルスチェックパスですが、以下Redashはデフォルトで/pingが用意されているので指定しましょう。
https://discuss.redash.io/t/aws-fargate-redash-server-alb/6152/6
- elb_listenerrule.tf
・移行前
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
resource "aws_lb_listener_rule" "hoge_https_rule_redash" { listener_arn = aws_lb_listener.hoge_https.arn priority = 7 action { type = "forward" forward { target_group { arn = aws_lb_target_group.redash.arn weight = 1 } target_group { arn = aws_lb_target_group.redash_fargate.arn weight = 0 } } type = "forward" target_group_arn = aws_lb_target_group.redash_fargate.arn } condition { host_header { values = ["redash.adachin.me"] } } } |
・移行後
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
resource "aws_lb_listener_rule" "https_rule_redash" { listener_arn = aws_lb_listener.hoge_https.arn priority = 7 action { type = "forward" target_group_arn = aws_lb_target_group.redash_fargate.arn } condition { host_header { values = ["redash.adachin.me"] } } } |
移行前と移行後のソースがありますが、リスナールールでEC2用とECS用のターゲットグループをいつでも切り替えられるようにしています。
- ecs_redash.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
## Redash(server & worker) resource "aws_ecs_task_definition" "redash" { family = "redash" requires_compatibilities = ["FARGATE"] network_mode = "awsvpc" task_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" execution_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" cpu = 2048 memory = 4096 container_definitions = templatefile( "files/task_definitions/redash.json", { s3_backup_bucket_arn : "arn:aws:s3:::hoge.adachin.me", dd_api_key : aws_ssm_parameter.datadog_api_key.arn } ) } resource "aws_ecs_service" "redash_service" { cluster = aws_ecs_cluster.redash.id deployment_minimum_healthy_percent = 50 deployment_maximum_percent = 200 desired_count = var.aws_ecs_service_desired_count_redash launch_type = "FARGATE" platform_version = "1.4.0" name = "redash-service" enable_execute_command = true health_check_grace_period_seconds = 300 lifecycle { ignore_changes = [ desired_count ] } load_balancer { target_group_arn = aws_lb_target_group.redash_fargate.arn container_name = "redash-server" container_port = 5000 } network_configuration { subnets = [ aws_subnet.hoge-private-1a.id, aws_subnet.hoge-private-1c.id, aws_subnet.hoge-private-1d.id ] security_groups = [ aws_security_group.redash.id ] } task_definition = aws_ecs_task_definition.redash.arn } ## Redash(scheduler) resource "aws_ecs_task_definition" "redash_scheduler" { family = "redash-scheduler" requires_compatibilities = ["FARGATE"] network_mode = "awsvpc" task_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" execution_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" cpu = 256 memory = 512 container_definitions = templatefile( "files/task_definitions/redash-scheduler.json", { s3_backup_bucket_arn : "arn:aws:s3:::hoge-adachin.me" } ) } resource "aws_ecs_service" "redash_scheduler_service" { cluster = aws_ecs_cluster.redash.id deployment_minimum_healthy_percent = 0 deployment_maximum_percent = 100 desired_count = var.aws_ecs_service_desired_count_redash_scheduler launch_type = "FARGATE" platform_version = "1.4.0" name = "redash-scheduler-service" enable_execute_command = true lifecycle { ignore_changes = [ desired_count, ] } network_configuration { subnets = [ aws_subnet.hoge-private-1a.id, aws_subnet.hoge-private-1c.id, aws_subnet.hoge-private-1d.id ] security_groups = [ aws_security_group.redash.id ] } task_definition = aws_ecs_task_definition.redash_scheduler.arn } |
まず、12行目では環境変数でバケットとdatadogのAPIkeyはAWS Systems Manager(SSM)のパラメータストアから値を取得しています。バケットでは後ほど説明するRedashのenvファイルを読み込ませるためです。
次に、25行目の health_check_grace_period_seconds = 300 ですが、Redashといえば起動する時間がかかるため、300秒の間はALBのヘルスチェックが失敗してもECSに無視してもらうように設定する必要があります。
また、71行目の deployment_minimum_healthy_percent = 0 は以下schedulerがローリングデプロイが不可能なため、旧コンテナを消してから新コンテナをデプロイするようにしています。
- files/task_definitions/redash.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
[ { "name": "redash-server", "image": "redash/redash:10.1.0.b50633", "cpu": 1019, "memory": 1920, "stopTimeout": 60, "memoryReservation": null, "environmentFiles": [ { "value": "${s3_backup_bucket_arn}/redash/.env", "type": "s3" } ], "environment": [ { "name": "REDASH_WEB_WORKERS", "value": "4" } ], "command": [ "server" ], "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "/ecs/redash/server", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "entryPoint": null, "portMappings": [ { "hostPort": 5000, "protocol": "tcp", "containerPort": 5000 } ], "dockerLabels": null }, { "name": "redash-worker", "image": "redash/redash:10.1.0.b50633", "cpu": 1019, "memory": 1920, "stopTimeout": 60, "memoryReservation": null, "environmentFiles": [ { "value": "${s3_backup_bucket_arn}/redash/.env", "type": "s3" } ], "environment": [ { "name": "QUEUES", "value": "default,scheduled_queries,schemas,queries,periodic,emails" }, { "name": "WORKERS_COUNT", "value": "4" } ], "command": [ "worker" ], "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "/ecs/redash/worker", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "entryPoint": null, "dockerLabels": null }, { "image": "datadog/agent:latest", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/datadog-agent", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "cpu": 10, "memory": 256, "mountPoints": [], "portMappings": [ { "hostPort": 8126, "protocol": "tcp", "containerPort": 8126 } ], "environment": [ { "name": "ECS_FARGATE", "value": "true" }, { "name": "DD_PROCESS_AGENT_ENABLED", "value": "true" }, { "name": "DD_DOGSTATSD_NON_LOCAL_TRAFFIC", "value": "true" }, { "name": "DD_APM_ENABLED", "value": "true" }, { "name": "DD_APM_NON_LOCAL_TRAFFIC", "value": "true" } ], "secrets": [ { "name": "DD_API_KEY", "valueFrom": "${dd_api_key}" } ], "networkMode": "awsvpc", "name": "datadog-agent" } ] |
- files/task_definitions/redash-scheduler.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
[ { "name": "redash-scheduler", "image": "redash/redash:10.1.0.b50633", "cpu": 0, "stopTimeout": 60, "memoryReservation": null, "environmentFiles": [ { "value": "${s3_backup_bucket_arn}/redash/.env", "type": "s3" } ], "command": [ "scheduler" ], "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "/ecs/redash/scheduler", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "entryPoint": null, "dockerLabels": null } ] |
- .env
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PYTHONUNBUFFERED=0 REDASH_LOG_LEVEL=INFO REDASH_REDIS_URL=redis://redash-redis.xxxxxxx.cache.amazonaws.com:6379/0 POSTGRES_PASSWORD=xxxxxxxxxx REDASH_COOKIE_SECRET=xxxxxxxxxxxxxxxxxx REDASH_DATABASE_URL=postgresql://hoge:xxxxxxxx@redash.xxxxxxx.ap-northeast-1.rds.amazonaws.com/redash REDASH_GOOGLE_CLIENT_ID=xxxxxxxxxxxxxxxxxxx REDASH_GOOGLE_CLIENT_SECRET=xxxxxxxxxxxxxxxxx REDASH_DATE_FORMAT=YYYY/MM/DD REDASH_FEATURE_SHOW_PERMISSIONS_CONTROL=true GUNICORN_CMD_ARGS="--timeout=120" REDASH_DISABLED_QUERY_RUNNERS="redash.query_runner.graphite,redash.query_runner.mongodb,redash.query_runner.couchbase,redash.query_runner.url,redash.query_runner.influx_db,redash.query_runner.elasticsearch,redash.query_runner.amazon_elasticsearch,redash.query_runner.trino,redash.query_runner.presto,redash.query_runner.databricks,redash.query_runner.hive_ds,redash.query_runner.impala_ds,redash.query_runner.vertica,redash.query_runner.clickhouse,redash.query_runner.yandex_metrica,redash.query_runner.rockset,redash.query_runner.treasuredata,redash.query_runner.sqlite,redash.query_runner.dynamodb_sql,redash.query_runner.mssql,redash.query_runner.mssql_odbc,redash.query_runner.memsql_ds,redash.query_runner.mapd,redash.query_runner.jql,redash.query_runner.axibase_tsd,redash.query_runner.salesforce,redash.query_runner.prometheus,redash.query_runner.qubole,redash.query_runner.db2,redash.query_runner.druid,redash.query_runner.kylin,redash.query_runner.drill,redash.query_runner.uptycs,redash.query_runner.snowflake,redash.query_runner.phoenix,redash.query_runner.json_ds,redash.query_runner.cass,redash.query_runner.dgraph,redash.query_runner.azure_kusto,redash.query_runner.exasol,redash.query_runner.corporate_memory,redash.query_runner.sparql_endpoint,redash.query_runner.firebolt" |
PYTHONUNBUFFERED はdocker-compose.ymlにも指定されているように、envファイルでも必要になります。また、Redashは多くのデータソースに対応している反面、依存パッケージも多いのと、読み込みによってメモリが多く消費されます。 REDASH_DISABLED_QUERY_RUNNERS で使われていない不要なクエリは削除してしまいましょう。
- autoscale.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
resource "aws_appautoscaling_target" "redash_ecs_target" { service_namespace = "ecs" resource_id = "service/${aws_ecs_cluster.redash.name}/${aws_ecs_service.redash_service.name}" scalable_dimension = "ecs:service:DesiredCount" role_arn = data.aws_iam_role.ecs_service_autoscaling.arn min_capacity = 1 max_capacity = 8 } resource "aws_appautoscaling_policy" "redash_scale_up" { name = "redash_scale_up" service_namespace = "ecs" resource_id = "service/${aws_ecs_cluster.redash.name}/${aws_ecs_service.redash_service.name}" scalable_dimension = "ecs:service:DesiredCount" step_scaling_policy_configuration { adjustment_type = "ChangeInCapacity" cooldown = 120 metric_aggregation_type = "Average" step_adjustment { metric_interval_lower_bound = 0 scaling_adjustment = 1 } } depends_on = [aws_appautoscaling_target.redash_ecs_target] } resource "aws_appautoscaling_policy" "redash_scale_down" { name = "redash_scale_down" service_namespace = "ecs" resource_id = "service/${aws_ecs_cluster.redash.name}/${aws_ecs_service.redash_service.name}" scalable_dimension = "ecs:service:DesiredCount" step_scaling_policy_configuration { adjustment_type = "ChangeInCapacity" cooldown = 120 metric_aggregation_type = "Average" step_adjustment { metric_interval_upper_bound = 0 scaling_adjustment = -1 } } depends_on = [aws_appautoscaling_target.redash_ecs_target] } resource "aws_cloudwatch_metric_alarm" "redash_cpu_high" { alarm_name = "redash_cpu_utilization_high" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = "1" metric_name = "CPUUtilization" namespace = "AWS/ECS" period = "60" statistic = "Average" threshold = "80" dimensions = { ClusterName = aws_ecs_cluster.redash.name ServiceName = aws_ecs_service.redash_service.name } alarm_actions = [aws_appautoscaling_policy.redash_scale_up.arn] } resource "aws_cloudwatch_metric_alarm" "redash_cpu_low" { alarm_name = "redash_cpu_utilization_low" comparison_operator = "LessThanOrEqualToThreshold" evaluation_periods = "1" metric_name = "CPUUtilization" namespace = "AWS/ECS" period = "60" statistic = "Average" threshold = "70" dimensions = { ClusterName = aws_ecs_cluster.redash.name ServiceName = aws_ecs_service.redash_service.name } alarm_actions = [aws_appautoscaling_policy.redash_scale_down.arn] } |
オートスケールは80%以上からですが、コンテナの起動が遅いので40%からでも良さそうですね。ここらへんは運用してから変えていきましょう。
EC2からECS/Fargateに切り替え
- EC2/docker-compose stopする
- DBをdumpする
- terraform apply
- ターゲットグループをfargate用に向ける
- アクセスできたらEC2をシャットダウンし、AMIとインスタンス削除
RedashはEC2とECSで同時起動してしまうとworkerのスケジューラーやクエリが走らないように必ずEC2の方は停止することをオススメします。
まとめ
これはTerraform化しないと手動での設定は無理なんじゃないかと思うくらい大変でした。ECSならではの設定項目があったりするので、マネージドに移行してからまだ運用して間もないですが、オートスケールなどの調整は引き継ぎDatadogでモニタリングしていこうと思います。とりあえず運用コストかからなくて済むぞ!(docker-composeの方が個人的に楽)
参考
https://zenn.dev/paulxll/articles/5acfafd0921f0b
https://tech.timee.co.jp/entry/2020/04/20/175821



0件のコメント