こんにちは!ファインディでSREチームをしている安達(@adachin0817)です。 この記事はFindy Advent Calendar 2024 13日目の記事です。12月といえば、私が飼っているフレンチブルドッグのBull氏が2歳を迎えました。この二年間、仕事しつつ、犬の面倒も見れたことを誇りに思います。
はじめに
さて、本題に入りますが、AWSでセキュリティ関連のログ(CloudTrailやWAFなど)を可視化して分析する際、独自実装では工数がかかってしまいます。SaaSモニタリングツールにログを転送して運用する方法もありますが、コストが高くなりやすい傾向があります。今回は、セキュリティログを簡単に一元管理できるAmazon Security Lakeを試してみました。導入の手軽さや運用性について、実際の使用感をブログします。
Amazon Security Lakeとは
https://aws.amazon.com/jp/security-lake/

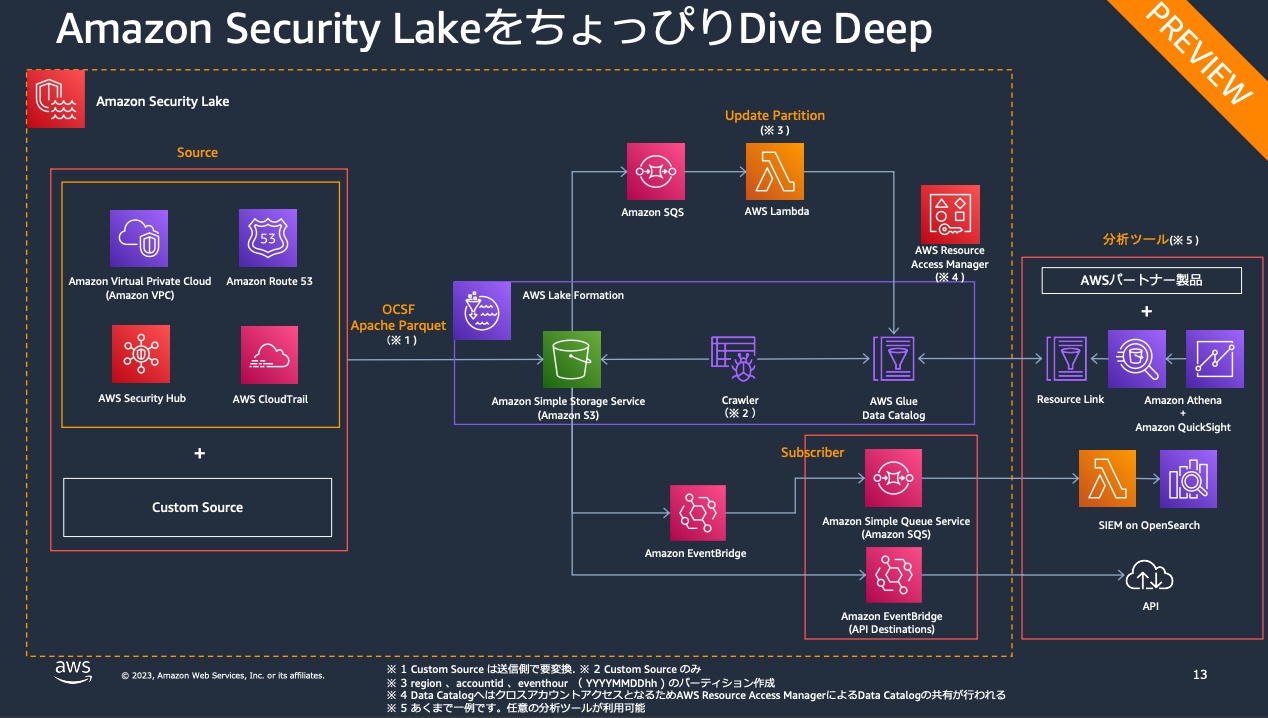
フルマネージド型のセキュリティデータレイクサービスで、AWSから収集したセキュリティデータ(ログやイベントデータ)を専用のデータレイクに自動で一元管理ができます。また、Open Cybersecurity Schema Framework (OCSF)、Apache Parquetに基づいてデータを標準化しているため、さまざまな分析ツールやセキュリティアプリケーションとの互換性が向上し、内部監査のニーズにも対応しやすくなります。基本、S3にログが格納され、GlueとAthenaを利用してGrafanaで分析するのがベストだと思うので、まずはTerraform化していきましょう。
- 対象サービス
- VPC Flow Log
- CloudTrail 管理イベントとデータイベント (S3、Lambda)
- Route 53 Resolver クエリログ
- EKS 監査ログ
- Security Hub 調査結果
Terraform(Amazon Security Lake)
- 構成図
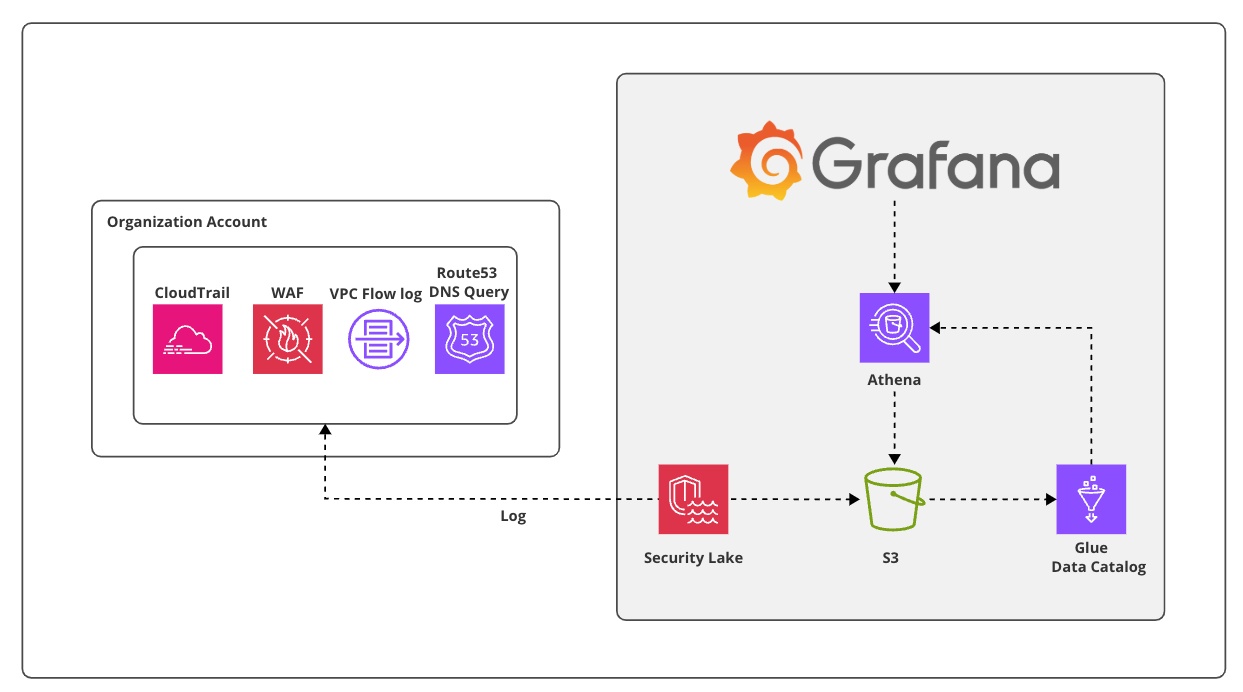
- ※前提条件
AWS Organizationsの有効化にする必要があります。管理アカウントからCloudTrailを有効と委任管理アカウントに対して、Amazon Security Lakeを有効化にします。その後、委任管理アカウントでSecurity Lakeの設定をする流れとなります。
- securitylake.tf
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/securitylake_data_lake
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
resource "aws_iam_role" "meta_store_manager" { name = "meta_store_manager_role" assume_role_policy = jsonencode({ Version = "2012-10-17", Statement = [ { Sid = "AllowLambda", Effect = "Allow", Principal = { Service = "lambda.amazonaws.com" }, Action = "sts:AssumeRole" } ] }) } resource "aws_iam_role_policy_attachment" "meta_store_manager_policy" { role = aws_iam_role.meta_store_manager.name policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonSecurityLakeMetastoreManager" } resource "aws_securitylake_data_lake" "securitylake_data_lake" { for_each = toset(local.enabled_regions) meta_store_manager_role_arn = aws_iam_role.meta_store_manager.arn configuration { region = each.value encryption_configuration { kms_key_id = "S3_MANAGED_KEY" } lifecycle_configuration { transition { days = 31 storage_class = "STANDARD_IA" } transition { days = 80 storage_class = "ONEZONE_IA" } expiration { days = 300 } } } } resource "aws_securitylake_aws_log_source" "securitylake_aws_log_source" { for_each = local.log_sources source { accounts = local.accounts_list regions = each.value source_name = each.key } depends_on = [aws_securitylake_data_lake.securitylake_data_lake] } |
まず、AWS Security Lakeのメタデータを管理するために必要なIAMロールを作成します。このロールはデータ加工でAWS Lambdaがこのロールを引き受けられるように設定されています。さらに、このロールにはAWSが提供する「AmazonSecurityLakeMetastoreManager」ポリシーをアタッチすることで、Security Lakeのメタストア管理機能を利用可能にしています。
次に、Security Lakeのデータレイクを設定します。このデータレイクは、指定されたAWSリージョンごとに構築され、それぞれがIAMロール「meta_store_manager_role」を使用します。データの暗号化には、S3の管理キー(S3_MANAGED_KEY)を採用し、データのライフサイクル管理も行います。具体的には、ストレージクラスをデータを31日後STANDARD_IA、80日後にONEZONE_IA、300日後に削除するようにしました。
- locals.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
locals { accounts_map = { for account in data.aws_organizations_organization.hoge.accounts : account.name => account.id } accounts_list = [ local.accounts_map["hoge-A"], local.accounts_map["hoge-B"], local.accounts_map["hoge-C"], ] } locals { enabled_regions = [ "ap-northeast-1", "ap-northeast-2", "ap-northeast-3", "ap-south-1", "ap-southeast-1", "ap-southeast-2", "ca-central-1", "eu-central-1", "eu-north-1", "eu-west-1", "eu-west-2", "eu-west-3", "sa-east-1", "us-east-1", "us-east-2", "us-west-1", "us-west-2" ] } locals { log_sources = { "CLOUD_TRAIL_MGMT" = local.enabled_regions, "LAMBDA_EXECUTION" = local.enabled_regions, "ROUTE53" = local.enabled_regions, "VPC_FLOW" = local.enabled_regions, "WAF" = local.enabled_regions } } |
AWSアカウントからセキュリティログを収集するために、複数のアカウントと全リージョンを対象に、CloudTrailやVPC Flow Logなどのセキュリティ関連ログを収集するように指定しました。この設定ではlocals.tfの内容を基に、ログソースごとの収集範囲を柔軟に指定できるようにしました。
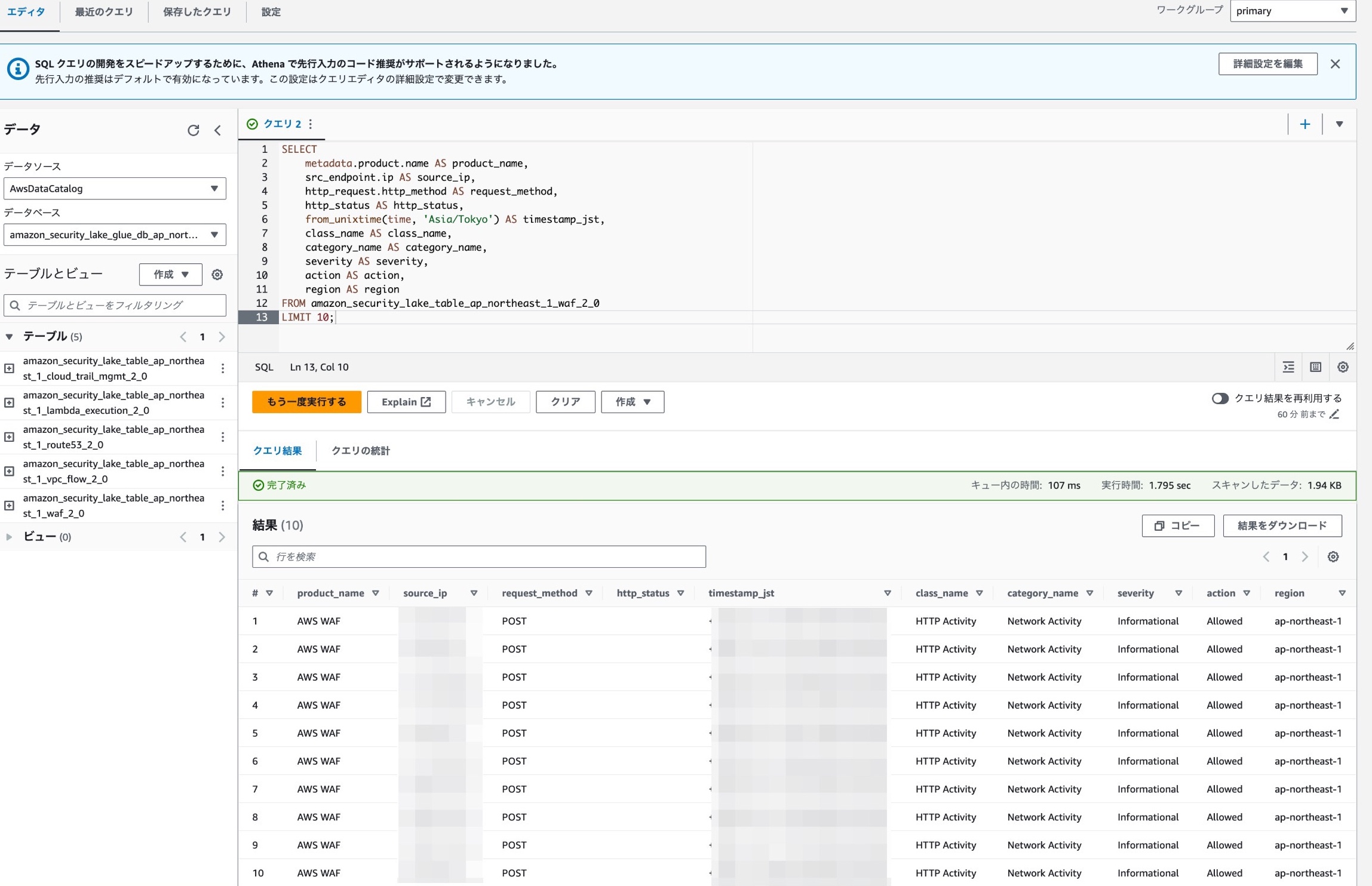
ちなみにリソース等すべて削除する場合は、GlueのDBとS3バケットを削除しないとTerraform側でエラーが止まらないので気をつけましょう。試しにAthenaでWAFのテーブルをクエリ叩くと以下のように値が出てくれば完了です。
- 動作確認
疑問点
実装していて、いくつか疑問点が浮かびましたので、AWSサポートに聞いてみました!
- VPC Flow LogやWAFのログを個別に有効化していないにもかかわらず、なぜ取得できているのか?
AWS内部でログを取得するためのストリームがあり、そこからデータを取り込んでいるとのことでした。
- これらのログを個別に有効化した場合に料金が二重に発生するのではないのか?
そのようなことはありませんでした。
- Terraformとの相性について
マネージドということもあって、AWS Security Lakeが内部的に多くのリソースを自動的に作成するため、これらをTerraformで管理する場合、terraform import を用いて個別にインポートする必要があり、管理が煩雑になる点が挙げられます。そのため、これらのリソースはTerraformで直接管理せず、AWSの管理に任せるほうが運用上適していると思われます。
- CloudTrail
- CreateServiceLinkedChannel
- Lambda
- CreateEventSourceMapping20150331
- CreateFunction20150331
- AddPermission20150331v2
- EventBridge (Events)
- PutRule
- PutTargets
- S3
- PutBucketNotification
- PutBucketEncryption
- PutBucketPublicAccessBlock
- PutBucketPolicy
- CreateBucket
- SQS
- SetQueueAttributes
- CreateQueue
- Glue
- CreateTable
- CreateDatabase
- Lake Formation
- GrantPermissions
- PutDataLakeSettings
- KMS
- CreateGrant
- Athenaのコストについて(パーティション)
パーティションの設定が適切でないと不要なコストがかかるのではないかと心配していました。しかし、DESCRIBE コマンドでテーブルを確認したところ、日付ごとに管理されたParquetファイルを参照しており、自動的に適切なパーティションが行われていることが分かりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
> DESCRIBE amazon_security_lake_table_hoge; # Table schema: # col_name data_type comment metadata struct<product: struct<version: string, name: string, vendor_name: string, feature: struct<name: string>>, event_code: string, uid: string, profiles: array<string>, version: string> time bigint time_dt timestamp cloud struct<region: string, provider: string> api struct<response: struct<error: string, message: string, data: string>, operation: string, version: string, service: struct<name: string>, request: struct<data: string, uid: string>> dst_endpoint struct<svc_name: string> actor struct<user: struct<type: string, name: string, uid_alt: string, uid: string, account: struct<uid: string>, credential_uid: string>, session: struct<created_time_dt: timestamp, is_mfa: boolean, issuer: string>, invoked_by: string, idp: struct<name: string>> http_request struct<user_agent: string> src_endpoint struct<uid: string, ip: string, domain: string> session struct<uid: string, uid_alt: string, credential_uid: string, issuer: string> policy struct<uid: string> resources array<struct<uid: string, owner: struct<account: struct<uid: string>>, type: string>> class_name string class_uid int category_name string category_uid int severity_id int severity string user struct<uid_alt: string, uid: string, name: string> activity_name string activity_id int type_uid bigint type_name string status string is_mfa boolean unmapped map<string, string> accountid string region string asl_version string observables array<struct<name: string, value: string, type: string, type_id: int>> # Partition spec: # field_name field_transform column_name asl_version identity asl_version region identity region accountid identity accountid time_dt_day day time_dt |
Terraform(AWS Managed Grafana)
https://aws.amazon.com/jp/grafana/
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/grafana_workspace
- grafana.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
resource "aws_iam_role" "grafana" { name = "grafana-assume" assume_role_policy = jsonencode({ Version = "2012-10-17", Statement = [ { Effect = "Allow", Action = "sts:AssumeRole", Principal = { Service = "grafana.amazonaws.com" } } ] }) } resource "aws_iam_role_policy" "grafana_data_access" { name = "grafana-data-access" role = aws_iam_role.grafana.name policy = jsonencode({ Version = "2012-10-17", Statement = [ { Sid = "AthenaQueryAccess", Effect = "Allow", Action = [ "athena:ListDatabases", "athena:ListDataCatalogs", "athena:ListWorkGroups", "athena:GetDatabase", "athena:GetDataCatalog", "athena:GetQueryExecution", "athena:GetQueryResults", "athena:GetTableMetadata", "athena:GetWorkGroup", "athena:ListTableMetadata", "athena:StartQueryExecution", "athena:StopQueryExecution" ], Resource = "*" }, { Sid = "GlueReadAccess", Effect = "Allow", Action = [ "glue:GetDatabase", "glue:GetDatabases", "glue:GetTable", "glue:GetTables", "glue:GetPartition", "glue:GetPartitions", "glue:BatchGetPartition" ], Resource = "*" }, { Sid = "AthenaS3Access", Effect = "Allow", Action = [ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload", "s3:PutObject" ], Resource = "*" }, { Sid = "LakeFormationAccess", Effect = "Allow", Action = [ "lakeformation:GetDataAccess" ], Resource = "*" ] }) } resource "aws_grafana_workspace" "grafana" { account_access_type = "CURRENT_ACCOUNT" authentication_providers = ["AWS_SSO"] permission_type = "SERVICE_MANAGED" role_arn = aws_iam_role.grafana.arn data_sources = ["ATHENA", "CLOUDWATCH"] configuration = jsonencode( { "plugins" = { "pluginAdminEnabled" = true }, "unifiedAlerting" = { enabled = false } } ) } |
- コスト
- $9
- ダッシュボードとアラートの作成と管理
- およびデータソースにアクセスするためのアクセス許可の割り当てのための管理者権限
- $5
- ダッシュボード、アラート、およびクエリデータソースを表示
- ワークスペースで他のアクションを実行することは不可
- $9
BIツールは、自前で運用すると荷が重いため、閲覧者であれば$5であるAWS Managed Grafanaを利用してAthenaやCloudWatchからのデータを取得し、ダッシュボードを作成できる環境にしました。セキュリティ強化のため、AWS SSOを利用した認証にしました。ちなみにGrafanaからDatabaseを参照できない場合は、以下LakeFormationのGrant Permissionを追加しないといけないため、Terraform化していきましょう。
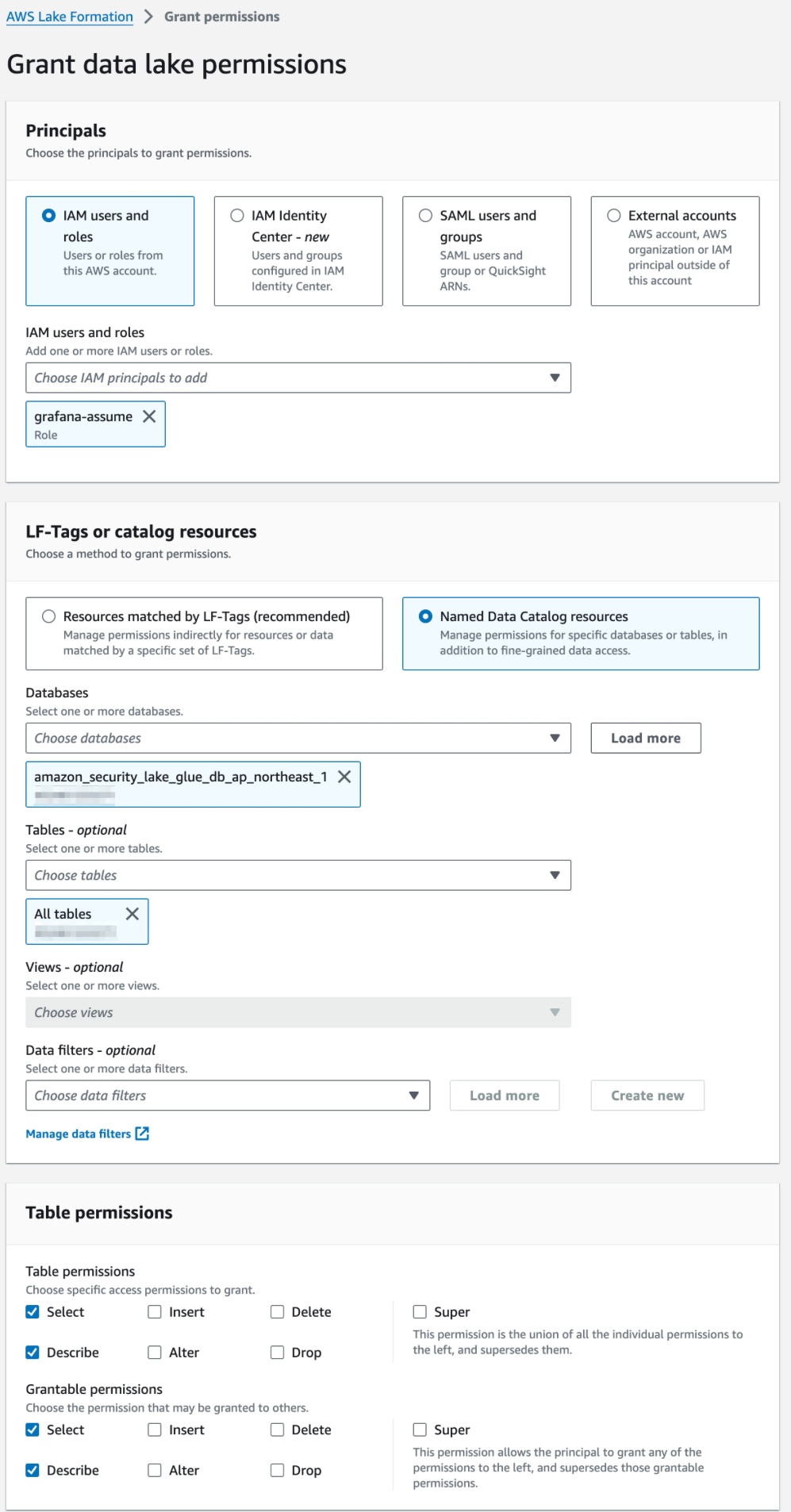
確認したところGrafanaロールに対して、LakeFormationの権限を追加すれば良さそうです!
- lakeformation.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
resource "aws_lakeformation_permissions" "security_lake_permissions" { principal = aws_iam_service_linked_role.security_lake_resource_management.arn permissions = ["ALTER", "DESCRIBE"] table { database_name = "amazon_security_lake_glue_db_ap_northeast_1" wildcard = true } } resource "aws_lakeformation_permissions" "grafana_permissions_ap_northeast_1" { principal = aws_iam_role.grafana.arn permissions = ["DESCRIBE", "SELECT"] permissions_with_grant_option = ["SELECT", "DESCRIBE"] table { database_name = "amazon_security_lake_glue_db_ap_northeast_1" wildcard = true } } |
- 動作確認
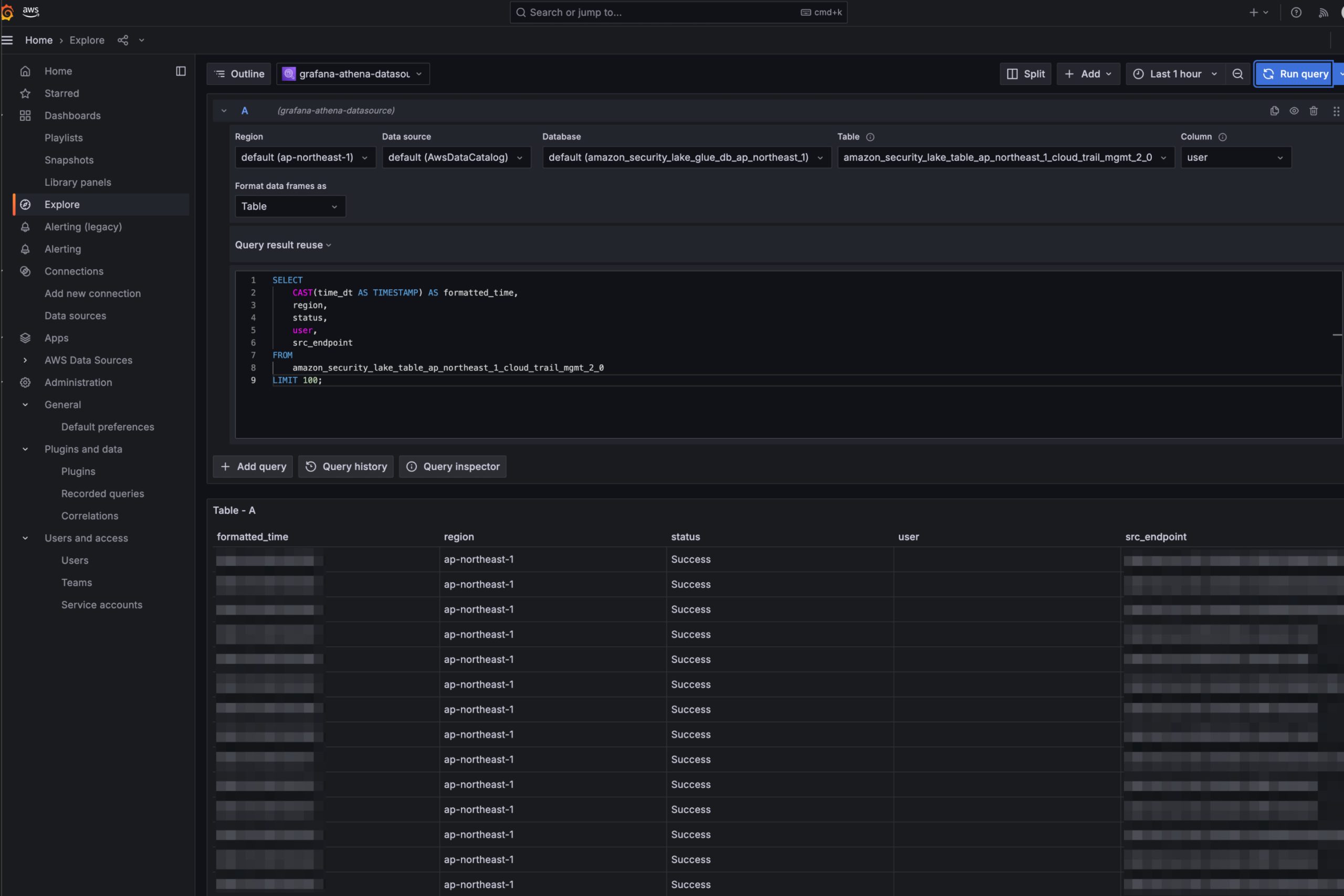
- Glueのパーティションが最新に更新されない場合
Lambda関数に対するトラフィックが増加してしまうと、一時的にLambda関数の実行の際にタイムアウトが生じてしまいます。また、Glueのパーティションが最新に更新されず、Athenaから最新のクエリが発行できなくなってしまいます。対応方法としては以下となります。
- Lambda 関数 (AmazonSecurityLakeMetastoreManager-ap-northeast-1) の “タイムアウト” の設定値を5 分から10 分に変更
- Lambda 関数のトリガーの設定にて、”バッチウィンドウ” を 300 に、”最大同時実行数” を 5 に変更
- SQSのPoll for messagesを全選択し、再実行
まとめ
Amazon Security Lakeはセキュリティデータの収集、分析を効率化し、統合的なセキュリティ基盤を実現するための強力なサービスであるのと、導入もシンプルであるなと感じました。セキュリティログ基盤の運用負担を軽減しつつ、コスト効率も両立できそうです。また、Grafanaでユーザーごとにテーブルの制限なども設計しなければならないので、追々ブログしていきます!
読んでいただきありがとうございました!明日の14日は@hyuta555さんです!



{kind=link}
0件のコメント