以前ランサーズエンジニアブログ
(https://engineer.blog.lancers.jp/2018/12/lancers-capybara/)
にて分析基盤について書きましたが、各サーバ(App)ログをLogサーバへ収集、S3にシンクする方法があまりにも画期的だったのでブログします。
■構成図
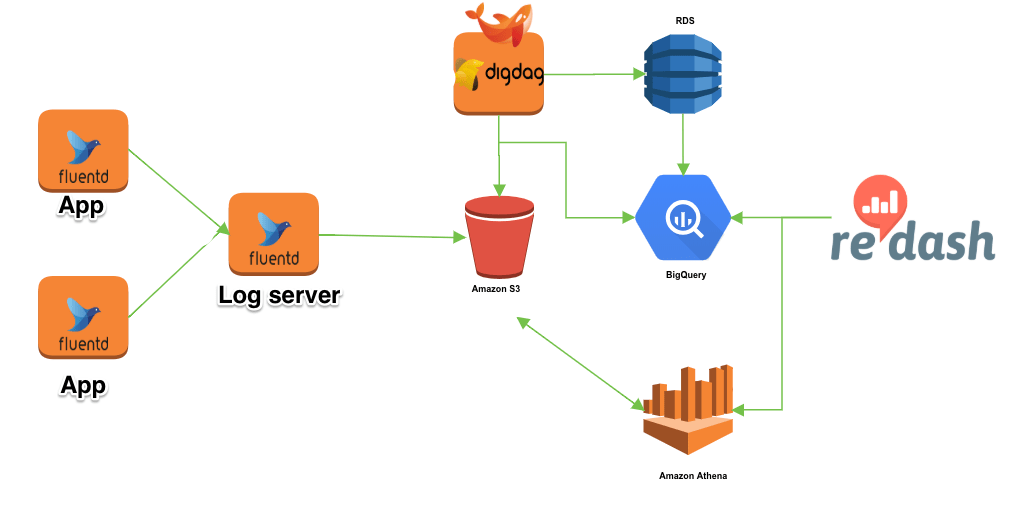
- プラグイン
- fluent-plugin-s3
- fluent-plugin-forest
■App/td-agent.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# nginx log <source> type tail format ltsv path /var/log/nginx/test_access.log pos_file /var/log/td-agent/tmp/test_access.log.pos keep_time_key true time_key time time_format %FT%T%:z tag adachin.log.nginx.test_access @label @forward </source> <source> type tail format /^(?<time>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[(?<log_level>\w+)\] (?<pid>\d+).(?<tid>\d+): (?<message>.*)$/ path /var/log/nginx/test_error.log pos_file /var/log/td-agent/tmp/test_error.log.pos tag adachin.log.nginx.test_error @label @forward </source> # copy log server <label @forward> <match adachin.*.*.*> type copy <store> type forward send_timeout 60s #イベントログを送信するときのタイムアウト時間。デフォルトは60秒 recover_wait 10s #サーバー障害回復を受け入れるまでの待機時間。デフォルトは10秒 heartbeat_interval 1s #ハートビートパッカーの間隔。デフォルトは1秒 phi_threshold 16 #サーバー障害を検出するために使用されるしきい値パラメーター。デフォルト値は16 hard_timeout 60s #サーバーの障害を検出するために使用されるハードタイムアウト。デフォルト値はsend_timeoutパラメータと同じ buffer_type file buffer_path /var/log/td-agent/buffer/log/ buffer_queue_limit 64 buffer_chunk_limit 8m flush_interval 5s #データフラッシュの間隔 disable_retry_limit false #バッファリングされたデータが破棄されるまでの再試行回数の制限 retry_limit 17 #バッファリングされたデータが破棄されるまで retry_wait 30s #書き込み再試行間の初期および最大間隔 require_ack_response true ## 受けて側のfluentdが正常に受け取ったか確認し成功と判断する <server> port xxxx host xxx.xxx.xxx.xxx </server> <secondary> @type file path /var/log/td-agent/forward-failed </secondary> </store> <store> @type relabel @label @backup </store> </match> </label> |
今回対象のログはnginxのアクセスログとエラーログが対象となります。Logサーバへ集約している理由としてはログ欠損がないようにfluentdで5秒ごとに転送しています。もちろんformatはltsv必須。
■Log server/td-agent.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# monitoring リソース監視 <source> @id in_monitor_agent @type monitor_agent bind 0.0.0.0 port xxxxx </source> # forward <source> @id in_forward @type forward port xxxxx </source> # nginx <match adachin.log.nginx.*> @id out_nginx_copy @type copy <store> @type forest subtype file_with_fix_path <template> path /var/log/td-agent/nginx/${tag_parts[3]}.log buffer_path /var/log/td-agent/buffer/${tag} append true flush_interval 1s @label @metrics </template> <case *.*.*.{access}> format ltsv </case> <case **> format json </case> </store> <store> @id out_nginx_relabel @type relabel @label @metrics </store> # s3 <label @metrics> <match adachin.{log,activity}.*.*> @id out_metrics_s3 @type forest subtype s3 <template> #type file_alternative s3_bucket xxxxxxxxxxxxx s3_region ap-northeast-1 # ex: adachin/log/nginx/access/dt=20191216/ path ${tag_parts[0]}/${tag_parts[1]}/${tag_parts[2]}/${tag_parts[3]}/ # 日時でディレクトリ作成 buffer_path /var/log/td-agent/buffer/s3/${tag} # forestプラグインでbuffer_pathを指定する際は必ずtagを含む format json include_time_key true time_key time time_slice_format dt=%Y-%m-%d/${tag_parts[2]}_${tag_parts[3]}_%Y%m%d.log # 日付毎にファイルの命名フォーマットを変える flush_at_shutdown true # buffer_typeがfileの場合プロセス停止時に全てのキューが吐く buffer_chunk_limit 1g # Queueに存在できるchunkの最大数、これに達するとログを受け取れなくなる </template> </match> </label> |
1行目のリソース監視している部分では、fluentdにはin_monitor_agentというfluentdの内部状態を監視するための標準組み込みインプットプラグインがあります。上記のように指定したIPアドレスとポートでWebサーバーが稼働し、fluentdの内部情報を参照できるようになります。
64行目のS3の設定ではデータをtagごとに分けてアップロードしたい場合に、s3 pluginだけではプレースホルダに対応できないので、fluent-plugin-forestプラグインを使ってあたかも対応できるようにしています。また、75行目のpathでも日時で全ての対象ログを引っ張ってきているので対象のログ指定することはなく、短いコードで書けます。(すごすぎる)
- S3
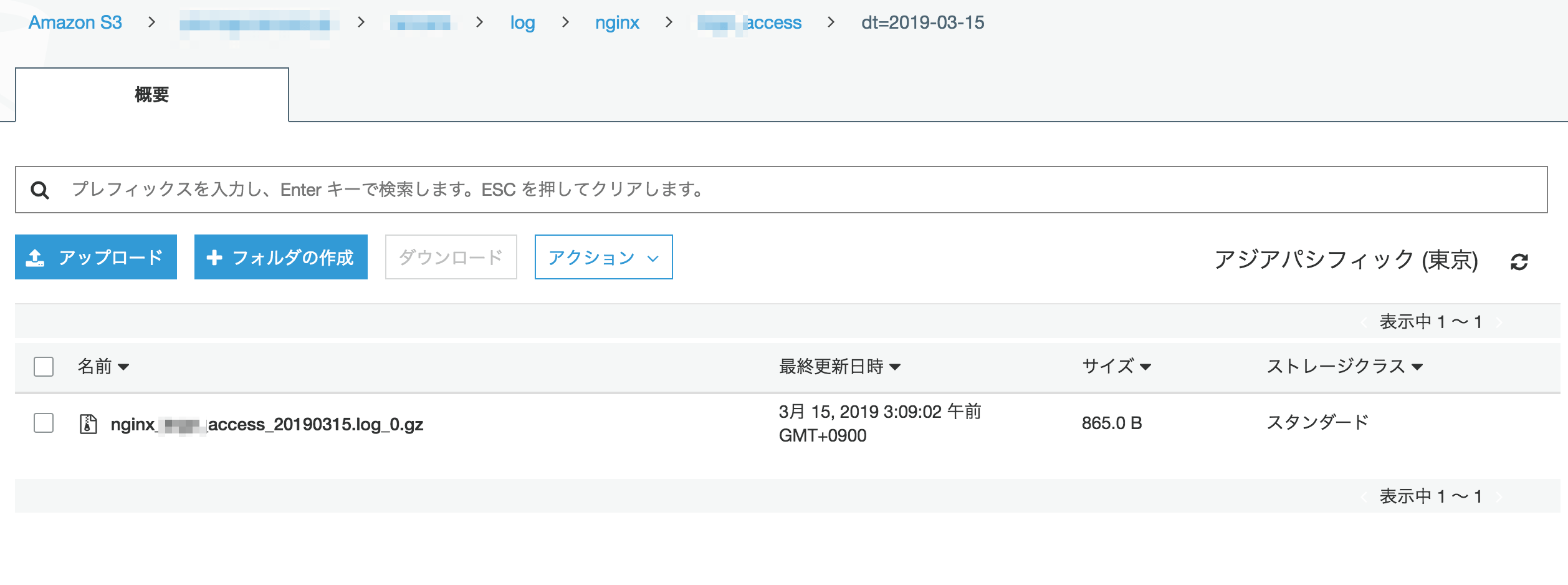
✌️
■まとめ
めちゃくちゃ画期的
fluentdは学習コストが高いので、理解すれば強い!



0件のコメント