Hi.Adachinです。
最近社内では・・・
「Spark!!Spark!(・∀・)」
「Sparkの本が出たぜ!(・∀・)」
Spark?なにそれおいしいの?(;・∀・)
まったく何を言っているのかわからんレベルでしたが、
Spark=Apache Spark
のことで、ウインドウ集計が安定でHadoopより優れている技術だそうです。
ちなみにcloudera社がサポートしており、今後はSparkが発展するみたいです。
で、そういえばHadoopのブログしてないなあと思い、概念とかかなりややこしいと思うので、
自分なりにまとめてみました。なので濃い内容となっております・・・
ゾウさんきゃわわ(・ω・)♡
■Hadoopとは
大規模データの蓄積、分析を分散処理技術によって実現するオープンソースのミドルウェア。
簡単に言うと膨大なデータを確認するのはかなりめんどくさいからゾウさんに任せよう!というわけです。
ちなみに、Clouderaの企業に加えて、intelやMicrosoftも開発が進められているそうです。
■Hadoopの歴史
元々はGoogleが論文として公開した社内の基盤技術をオープンソースとして実装したものを我々が利用しているわけです。
- GFS(Google File System Googleの分散ファイルシステム)
- Google MapReduce(Googleでの分散処理技術)
これらの論文をもとに、
Doug Cuttingさん(以下画像)(Apacheコミュニティの議長)を中心としたメンバーがJavaベースで開発したものが始まりです。

そして!Dougさんは以下のコンポーネントを開発しました。
-
HDFS (Hadoop Distributed File System : Hadoop分散ファイルシステム)
-
Hadoop MapReduce Framework(Hadoop MapReduceフレームワーク)
ちなみに・・・
なんでゾウさんなのかというとお子さんが持っていたお気に入りのぬいぐるみの象の名前が「Hadoop」だからそうです。
にしてもHadoop!Hadoop!とか名前かっこ良すぎ。
■Hadoopの特徴
特徴①
- 簡単なサーバ追加によってスケーラビリティを実現
|
1 |
HDFS(下記に説明してます)の容量や分散処理のためのリソースが不足する場合、サーバを追加することで容量および処理性能の向上が可能。 <strong>サーバの追加はHadoopクラスタの停止を必要とせず</strong>、サービスを継続した状態での運用が可能。 また、アプリケーションや基盤設計に影響を及ぼすことなく、新たにスケーラビリティを得ることができる。 |
簡単に言うと、ヤバイ容量がない!サーバ増やすぞ!ポチポチ・・・簡単(・∀・)
特徴②
- 非定型データの格納を想定した処理の柔軟性を実現
|
1 |
従来型のRDBMSやDWHと根本的に異なる点は、HDFSにデータを格納する際にはスキーマ定義が不要。 そのため、事前の設計の手間を低減することが可能。 Hadoopでは処理するタイミングでHDFSに格納したデータにその都度意味づけするので、 格納して、処理の方針が決まった際にデータの扱い方を定義することができる。 |
ちなみにRDBMS(relational database management system)
DWH(data warehouse)です!
簡単に言うと、設計するときにあれこれ考えず、処理するタイミングで勝手にデータ扱いにしてくれるということ。
特徴③
- 耐障害性
|
1 |
Hadoop環境を構成するサーバは専用ハードウェアや特別なスペックを必要なく、市販で入手できるサーバを利用することで、基盤構築の費用を抑えられる。また、大量のサーバを利用する際にはサーバ故障時の扱いに気を付けなければならないが、 Hadoopは故障発生を前提としたアーキテクチャであるため、任意のサーバが故障しても システム全体として問題なく動作する。 |
とりあえず万能だということが分かりますね!
■Hadoopを構成するコンポーネント
- HDFS
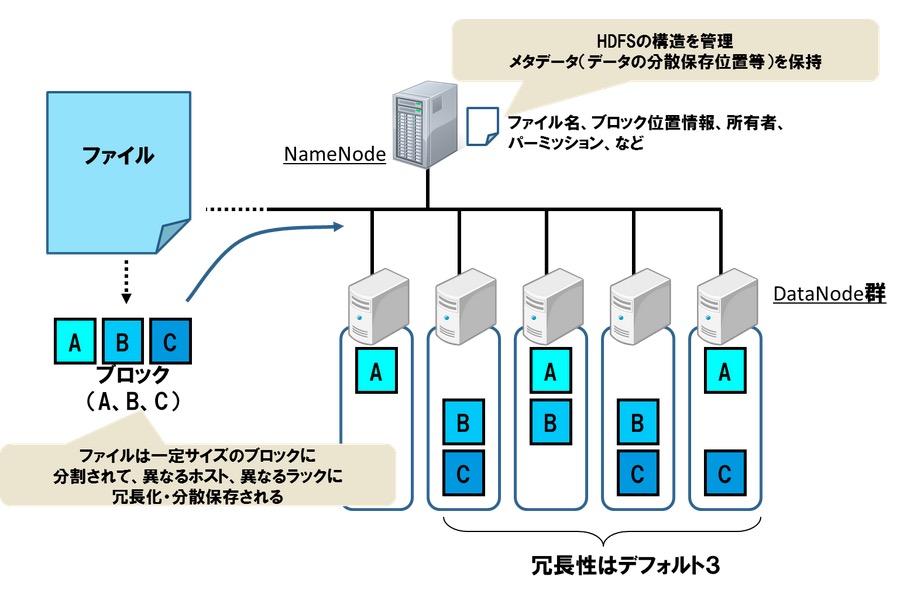
マスターノードであるNameNodeとスレーブノードであるDataNodeで構成されている。 NameNodeは分散ファイルシステムのメタ情報を管理し、DataNodeはデータの実体を保存。 HDFSにファイルを格納する場合、ファイルを一定サイズで分割したデータをブロックとしてDataNodeで保存。
また、任意のDataNodeが故障してもDataNodeで保存されているブロックが消失する可能性を考慮して、 ブロックは複数のDataNodeにレプリカを保存される。これにより任意のDataNodeが壊れた場合でも、 他のDataNodeの同じブロックを参照することができ、データの欠損を防ぐ仕組みになっている。
さらに HDFSはデフォルトで3つのレプリカをDataNodeで保存。
このレプリカ数はHDFSに格納するファイル単位で変更することが可能。
- Hadoop MapReduce(処理基盤)

Hadoop MapReduceはマスターノードであるJobTrackerとスレーブノードであるTaskTrackerで構成されており、 JobTrackerはMapReduceジョブの管理やTaskTrackerへのタスクの割り当て、TaskTrackerのリソース管理を役割としている。 TaskTrackerはタスクの実行を役割としてる。
MapReduce処理基盤ではTaskTrackerが故障し、そのTaskTrackerで実行していたタスクが完了できない場合はJobTrackerが他のTaskTrackerに同じタスクを割り当てる。これによりMapReduceジョブ全体を最初からやり直す必要がなく、継続して実行することが可能。
JobTrackerがTaskTrackerにタスク(mapタスク)を割り当てる際にはTaskTrackerが動作しているサーバと同居しているDataNodeが管理しているデータを極力利用するように割り当てる。これをデータのローカリティと呼ぶ。 TaskTrackerと同居しているDataNodeのデータを利用することで、サーバ間の通信量を極力抑えることが可能となり、オーバヘッドを抑える。 一方、reduceタスクは複数のTaskTrackerからデータを取得する必要があるため、mapタスクのようなデータのローカリティを考慮できない状態。
- Hadoop MapReduce(アプリケーション)
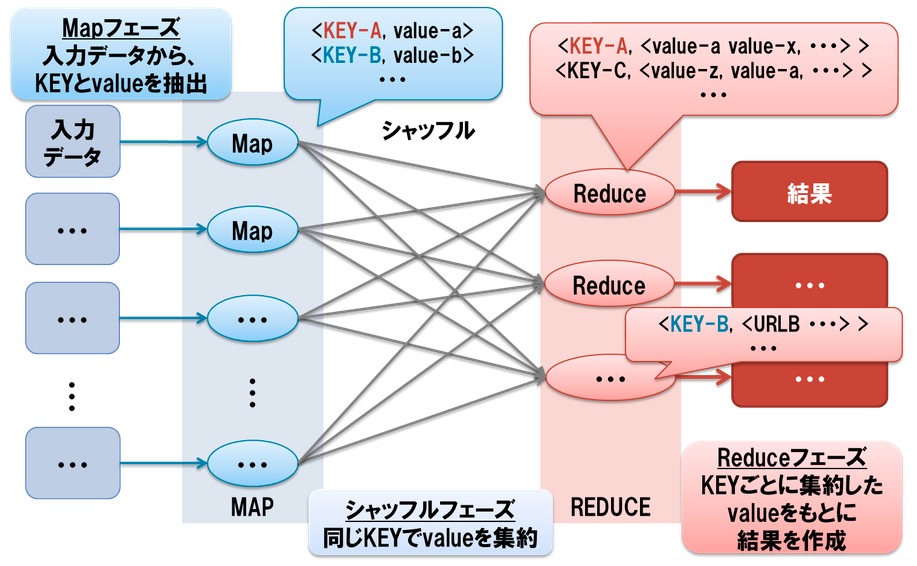
ちなみにこのアプリケーションは3つのジョブから構成されてます。
- map処理 : 入力データに対して、何らかの処理によってキー・バリューの形式でデータを意味づける
- reduce処理 : map処理のキーごとに集約されたデータに対して何らかの処理を実行する
- MapReduceジョブ定義 : 1と2を処理するための情報(入力パス、出力パス、reduce処理の多重度など)を定義するそして!!!!
- YARN
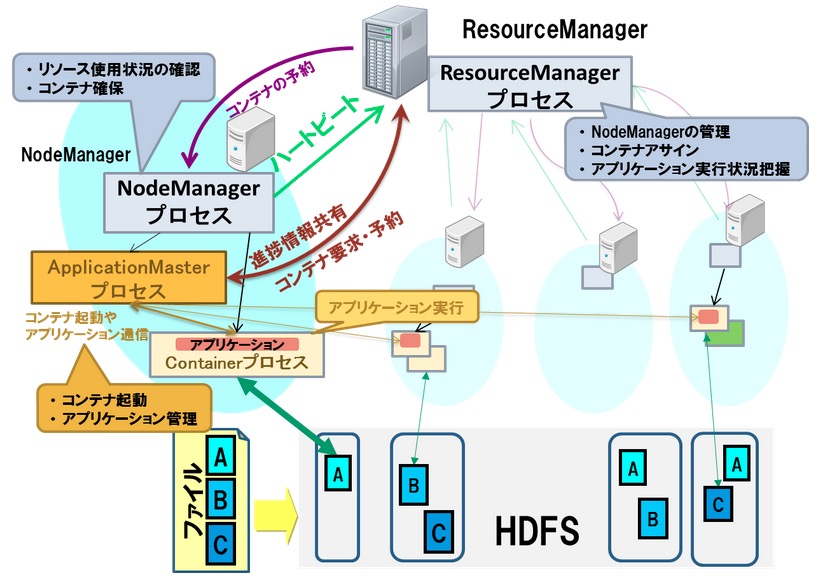
YARNの登場により、MapReduceに適していない処理については各自が仕組み(ApplicationMasterとアプリケーション制御)を実装することでMapReduceと同様にYARNの仕組みによって分散処理が可能となった!!!
YARNでは、Hadoopクラスタ内のリソースを管理するマスタノードとしてResourceManager、処理ノードを管理するスレーブノードとしてNodeManagerで構成されている。 アプリケーションを管理するノードApplicationMasterはリソース状況を確認しつつ処理を実行するContainer(コンテナ)の確保をResourceManagerに要求し、 ResourceManagerはNodeManagerからのリソース利用状況をもとに、どのノードでContainerを起動するか情報を回答する。 この回答を従い、ApplicationMasterは処理ノードでコンテナ起動を要求してアプリケーションを実行。
・どのくらいよくなったのか?
1.アプリケーションの集中管理によるマスタノードのボトルネックが解消
2.多数の処理ノードによりHadoopクラスタを構成することが可能
Hadoop 1系での仕組みだと3000~4000ノードがクラスタの限界だったが、10000ノード程度のクラスタも構成することが可能!!
■まとめ
今回のブログはこんな技術だったのかあ、へえーでいいと思います。
あとは実際に作って運営しないとまったく分かりませんね。。さらに、
Cloudera Managerの使い方ができても仕組みを理解してないとダメですね。
sparkの勉強もしないと・・・
最近はHDFS上にあるログをバックアップするスクリプトとか作りましたよ。githubにあります。
にしてもムズイ・・・
参考:http://www.atmarkit.co.jp/ait/articles/1408/18/news017.html
http://itpro.nikkeibp.co.jp/article/COLUMN/20120306/384802/
http://www.slideshare.net/hamaken/hadoop-cloudera-world-tokyo-2014
http://oss.nttdata.co.jp/hadoop/hadoop.html

0件のコメント