Hi Adachinです。
Apache Sparkについてまとめていきたいと思います。
最近はビックデータをどう処理するか課題となっていますが、(ツイートの集計とかetc)
さらにMap Reduceだと性能が発揮出来ず。。。(繰り返し処理の場合)
Sparkさんの出番だ!という感じでございます。
そもそもSparkとはなんなのか、Sparkってそんなにすごいの、など概念が分かればOKです。
あとはCloudera managerでの使い方ですね。。。それは置いときましょう!(;・∀・)
■Apache Sparkとは
Apache Hadoopを補完してビッグデータアプリケーションなどのバッチ処理やストリーム処理の統合、迅速な開発を実現し、すべてのデータのインタラクティブ分析を可能にするオープンソースの並列データ処理フレームワークのこと。
とりあえず、HDFSに特殊なキャッシュを乗っけて、やたらデータ処理が早いという認識でOK
ちなみに、
ClouderaはDatabricks社とのコラボにより、Cloudera Enterpriseを通じてSparkの商用サポートを提供してるそうです。

■Apache Sparkの特徴
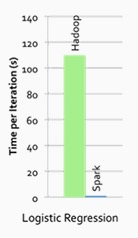
・高速
インメモリとディスクの両方において、MapReduceよりも最大で100倍速いデータ処理を実現
・パワフル
”map”と”reduce”の実行という点のみを考慮することなく、Java、ScalaやPython上の精巧な並列アプリケーションを迅速に実行
・統合性
Sparkは、CDHと深く統合されており、HDFSやCloudera Managerによってデプロイされたどんなデータも実行することが可能
100倍って・・・Hadoopぼっちだとオソスギ・・・
■Sparkストリーミング(リアルタイム処理)がすごい!
ストリーム処理で動作するAPIとともにSparkを拡張し、セマンティクスとミッションクリティカルな環境における完全な耐障害性を提供。
バッチ処理とストリーミング・アプリケーションの両方にわたる共通のコードを利用することで、精巧に統合された分析アプリケーションを、迅速かつ容易に構築することも可能。
(ウインドウ集計より)
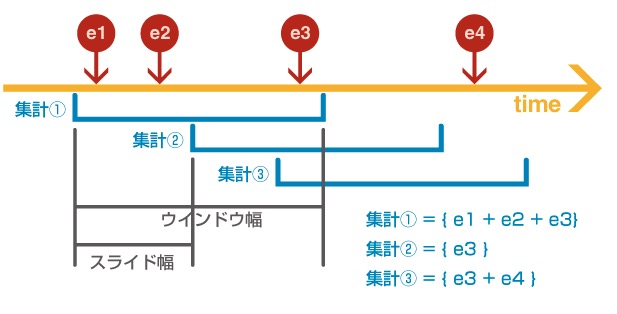
・簡易性
Sparkの構築は強力なAPI群にも関わらず軽量であり、ストリーミング・アプリケーションの迅速な開発を可能。
・耐障害性(フォールト・トレラント)
Stormのような他のストリーミング・ソリューションと違い、中断で飛んでしまった処理をリカバーし、余分なコードや環境設定を必要とすることなく即利用できるセマンティクスを提供。
・統合性
バッチ処理やストリーム処理のために同じコードを再利用することや、履歴データにストリーミングデータを統合することも可能。
要は手軽に集計ができるということですね〜
例えば「10秒間でのトラフィックを見たいとか、来客人数を知りたいとか」etc
■Cloudera エンタープライズデータハブ
強力なエンド・トゥ・エンドの分析ワークフロー、バッチデータ処理の構成、インタラクティブなクエリ、高度なデータマイニングを実現し、単一の共通プラットフォーム上ですべてのリアルタイム・アプリケーションの実行が可能。
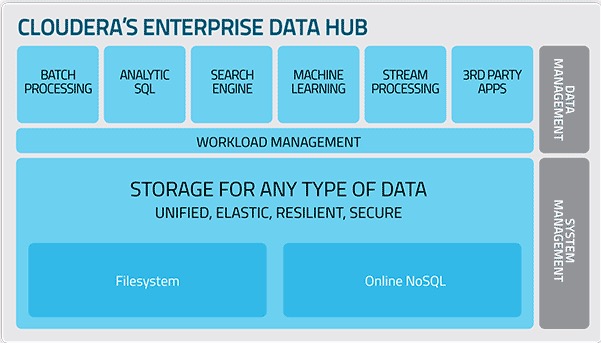 しかも!分離されたデータやメタデータなど保守はしなくていいので、管理が楽。
しかも!分離されたデータやメタデータなど保守はしなくていいので、管理が楽。
■まとめ
このApache Sparkを使うことで、
「より高速なバッチ処理、分析、Hadoopの上でストリーム処理を可能」になる!

ということから、IT業界で話題となっておりますっ!(・∀・)
ちなみにCDH5~からはすでにsparkが入っています。
4前はCloudera managerだとparcelから手動でインストールしないといけません!
参考:http://www.cloudera.co.jp/products-services/cdh/apache-spark.html
http://www.intellilink.co.jp/article/column/bigdata-kk01.html
http://www.slideshare.net/hadoopxnttdata/apache-spark-spark

0件のコメント