BI(分析)基盤を運用していると必ず起こるのが、日々のレコード数上昇によりBigQueryへのシンクが遅くなってしまうということです。実際にRDS(MySQL)のレコード数はどのくらいあるのか調査してみたところ、1000万レコードもあるテーブルが複数存在しており、シンクも1時間半くらいかかっていました。こうなる前に差分更新により、前日のデータをシンクするように作れば高速になるので、今回対象のテーブルを改善するべく方法と注意点をまとめてみます。
■構成
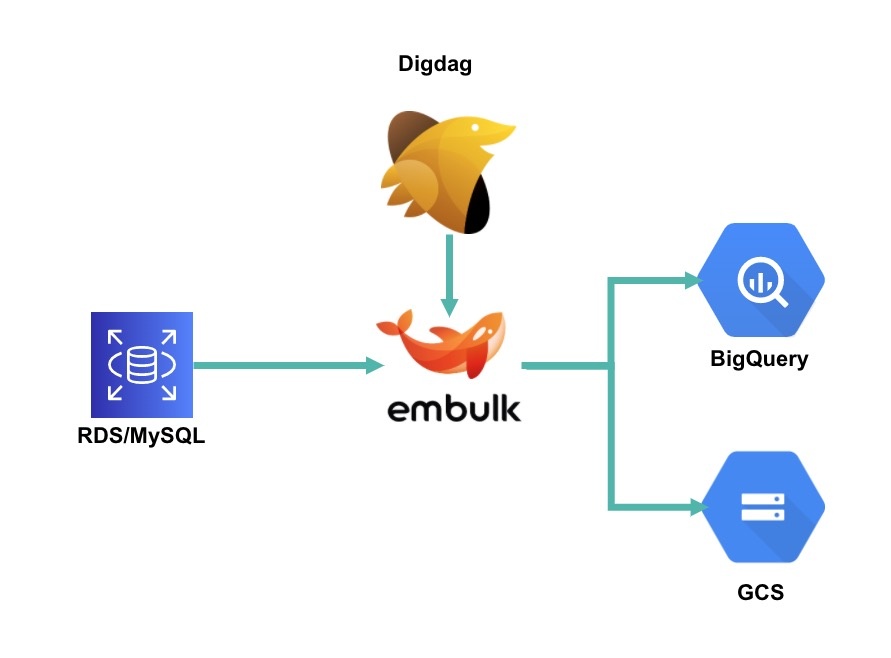
Digdagのバッチで、EmbulkがRDS(MySQL)のテーブルをガツンとBigQueryにシンクしています。これを前日分のみをシンクするとなると以下のような流れになります。
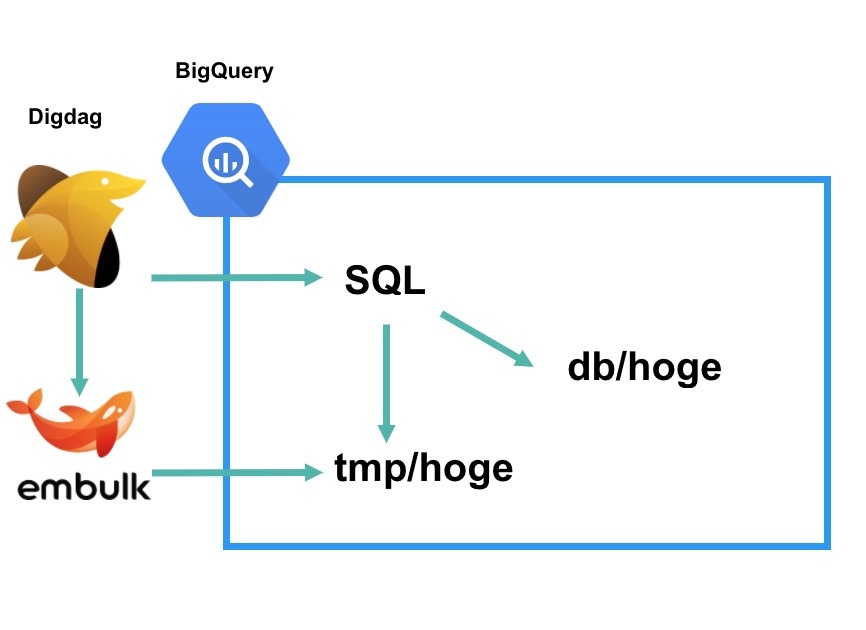
まずEmbulkでhogeテーブルだとしましょう。このテーブルをBigQueryにtmpというデータセットを作り、その中で前日分のhogeテーブルをシンクします。あとはDigdagから2つのテーブルを union all で結合して、主キーで partition by で行を追加します。BigQueryにはupdateの概念がないのでこのようなテクニックで実装することができます。では実際にコードを見てみましょう。
■Digdag/Embulk
- embulk/hoge.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
in: type: mysql {% if env.EMBULK_ENV == 'production' %} {% include 'db/prod_adachin' %} {% else %} {% include 'db/stg_adachin' %} {% endif %} query: | SELECT id,user_id,name,created,modified FROM hoge WHERE modified > DATE_SUB(CURDATE(), INTERVAL 1 DAY) out: type: bigquery mode: replace auth_method: json_key json_keyfile: /digdag/aurora_to_bigquery/config/bq.key {% if env.EMBULK_ENV == 'production' %} {% include 'db/prod_bigquery' %} {% else %} {% include 'db/stg_bigquery' %} {% endif %} auto_create_dataset: true auto_create_table: true dataset: tmp table: hoge schema_file: /digdag/aurora_to_bigquery/embulk/db/hoge.json open_timeout_sec: 300 send_timeout_sec: 300 read_timeout_sec: 300 auto_create_gcs_bucket: false gcs_bucket: {{ env.EMBULK_OUTPUT_GCS_BUCKET }} compression: GZIP source_format: NEWLINE_DELIMITED_JSON default_timezone: "Asia/Tokyo" |
13行目 でWHEREを使ってINTERVAL 1 DAYを指定します。 28行目 はtmpに変更してあげましょう。
- hoge.dig
|
1 2 3 4 5 6 7 8 9 10 |
_error: sh>: /digdag/post_slack.sh "[${session_time}][${session_id}] DigDag Fail hoge" +uploads: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/hoge.yml.liquid +transform: bq>: queries/hoge.sql destination_table: hoge_db.hoge write_disposition: WRITE_TRUNCATE |
7行目 のtransformを使って、下記のSQLを叩くように実際に格納するテーブルに行を追加するわけですね。
- queries/hoge.sql
|
1 2 3 4 5 6 7 8 |
select id,user_id,name,created,modified from ( select *,row_number() over (partition by id order by modified desc) as rn from (select * from `tmp.hoge` union all select * from `hoge_db.hoge`) ) where rn = 1 |
このSQLではidカラムの固まりであるPartitionの中から行番号の1行目(並び順:modified desc)(1行目:rn = 1 )を抽出して、union allで前日差分と全データを結合しています。
ちなみに私の場合だと、そのテーブルにidカラムがなく、user_idカラムで差分更新しようとしていたのでユーザーに対して、1レコードしか作られなくなる=レコード消えるということになりました。これは危ない。。基本idカラムで抽出条件を作るように気をつけましょう。
■まとめ
差分更新により1時間半のシンクが3分になりました!激速っ!今後は500万レコードくらいになったら差分更新するよう改善していけば良さそうですね。しかし運用大変だ。



0件のコメント