さて、2ヶ月ぶりのブログとなります。今回は分析基盤についてお話できればと思います。私個人の経験の中で分析基盤の知見を得られたのは現職のおかげでもありますが、Digdag、Embulk、BigQueryを利用せずに、AWS内で完結したい場合はどのような仕組みで実装すれば良いのだろうと経験なかったので、検証がてら試してみました。
昔はEmbulkのブログめっちゃ書いてましたね。
https://blog.adachin.me/archives/category/embulk
構成
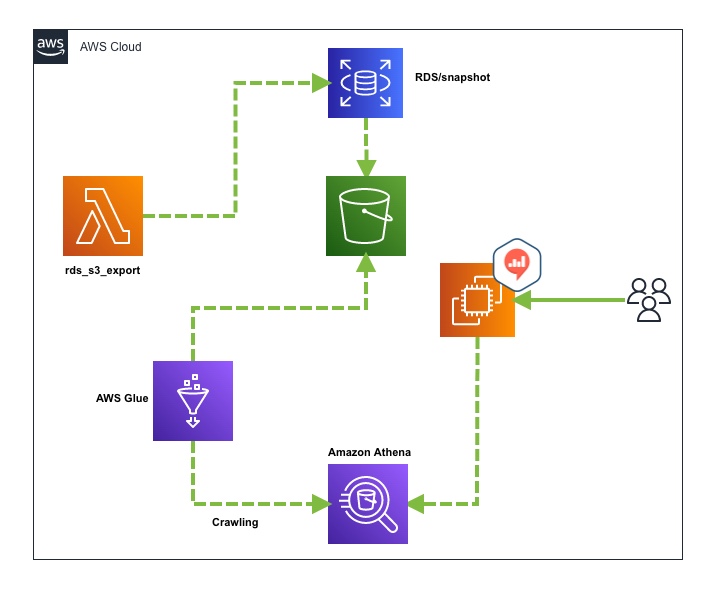
- Lambda(Python3.9)
- EventBridge Rule
- KMS
- RDS(snapshot)
- S3
- AWS Glue
- Amazon Athena
- Redash
https://docs.aws.amazon.com//AmazonRDS/latest/UserGuide/USER_ExportSnapshot.html
RDSにはスナップショットからS3にエクスポートする機能があり、AWS Glueのクローラーを利用してAthenaにデータを蓄積することが可能です。またエクスポート時も、対象のテーブルに絞ったり、差分更新なども可能です。Embulkと比べるとテーブル追加時に設定ファイルを書く必要はないので、運用工数がかからないというのがメリットです。デメリットは構成がシンプルではないので、設定が多すぎるのとTerraformによるコード化が必須となります。それではいってみましょう。
Terraform
まずはAthenaからS3に参照できるようにAWS Glueを追加します。
※ちなみにバケット名はhoge
- files/assume_role_policy/export-rds-s3-glue.json
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } |
- files/assume_role_policy/export-rds-s3.json
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } |
- files/assume_role_policy/glue-s3.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::hoge/*" ] } ] } |
- files/assume_role_policy/kms-glue.json
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "kms:Decrypt", "Resource": "arn:aws:kms:ap-northeast-1:xxxxxxx:key/xxxxxxxxxxxxxxxxxx" } ] } |
- glue.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
resource "aws_glue_catalog_database" "hoge_db" { name = "hoge_db" } resource "aws_glue_crawler" "hoge_db" { database_name = aws_glue_catalog_database.hoge_db.name name = "hoge_db" role = aws_iam_role.export_rds_s3_glue.arn schedule = "cron(00 20 * * ? *)" s3_target { path = "s3://${aws_s3_bucket.hoge.bucket}" } } |
- iam.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
## export-rds-s3 resource "aws_iam_role" "export_rds_s3" { name = "export-rds-s3" assume_role_policy = file("files/assume_role_policy/export-rds-s3.json") } resource "aws_iam_role_policy_attachment" "export_rds_s3" { role = aws_iam_role.export_rds_s3.name policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess" } ## export_rds_s3_glue resource "aws_iam_role" "export_rds_s3_glue" { name = "export-rds-s3-glue" assume_role_policy = file("files/assume_role_policy/export-rds-s3-glue.json") } resource "aws_iam_policy" "kms_glue" { name = "kms-glue" description = "kms-glue" policy = file("files/assume_role_policy/kms-glue.json") } resource "aws_iam_role_policy_attachment" "kms_glue" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = aws_iam_policy.kms_glue.arn } resource "aws_iam_policy" "glue_s3" { name = "glue-s3" description = "glue-s3" policy = file("files/assume_role_policy/glue-s3.json") } resource "aws_iam_role_policy_attachment" "glue_s3" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = aws_iam_policy.glue_s3.arn } data "aws_iam_policy" "s3_fullaccess" { name = "AmazonS3FullAccess" } resource "aws_iam_role_policy_attachment" "export_rds_s3_glue_s3_fullaccess_attach" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = data.aws_iam_policy.s3_fullaccess.arn } data "aws_iam_policy" "athena_fullaccess" { name = "AmazonAthenaFullAccess" } resource "aws_iam_role_policy_attachment" "export_rds_s3_glue_athena_fullaccess_attach" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = data.aws_iam_policy.athena_fullaccess.arn } data "aws_iam_policy" "glue_servicerole" { name = "AWSGlueServiceRole" } resource "aws_iam_role_policy_attachment" "export_rds_s3_glue_servicerole_attach" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = data.aws_iam_policy.glue_servicerole.arn } data "aws_iam_policy" "glue_consolefullaccess" { name = "AWSGlueConsoleFullAccess" } resource "aws_iam_role_policy_attachment" "export_rds_s3_glue_consolefullaccess_attach" { role = aws_iam_role.export_rds_s3_glue.name policy_arn = data.aws_iam_policy.glue_consolefullaccess.arn } |
見て分かると思いますが、IAMロールとポリシーまみれとなっております。セキュリティ的にS3にエクスポートする際のデータは既存のKMSを利用して暗号化するのがベストです。Parquet形式になっているので、データ分析する際便利ですね。また、Glueのスケジュールは朝の5時にしました。以下のように手動でエクスポート後、GlueのクローリングでAthenaに読み込ませれば完了となります。
- 確認
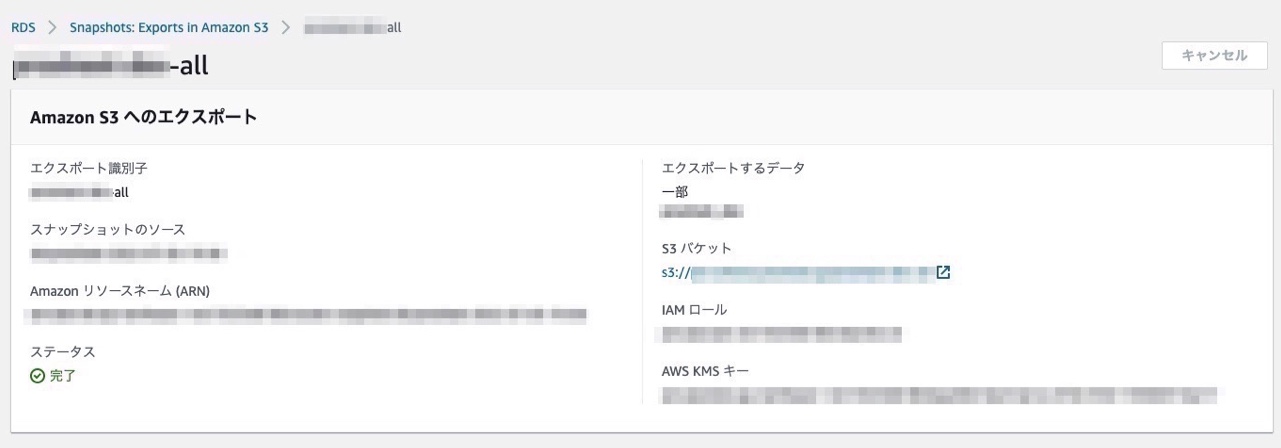
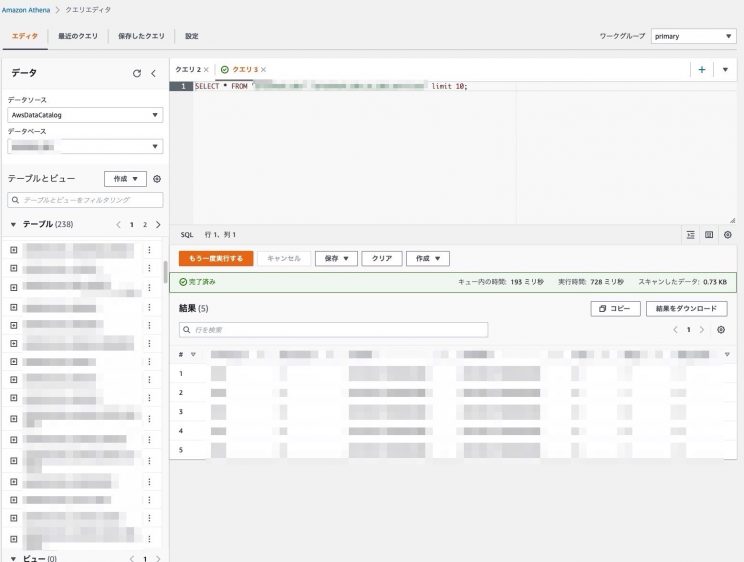
BigQueryと同じでクエリも問題なく叩けますね。viewテーブルも以下のようにクエリを実行すれば作成することが可能です。
- viewの作成
|
1 2 3 |
CREATE VIEW "hoge_users_view" AS SELECT * FROM "hoge_users" |
上記実装できたら次は手動で毎回エクスポートするにはいかないので、Lambdaで定期実行するように作ってみました。
Lambda/Terraform
- files/assume_role_policy/kms.json
|
1 2 3 4 5 6 7 8 |
省略 "Principal": { "AWS": [ "arn:aws:iam::${account_id}:user/s3" "arn:aws:iam::${account_id}:role/lambda_rds_s3_export_role" #追加 ] }, 省略 |
- files/assume_role_policy/lambda.json
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } |
- files/assume_role_policy/lambda_rds_s3.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole", "rds:StartExportTask" ], "Resource": "*" } ] } |
- files/assume_role_policy/lambda_rds_s3_execution.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "logs:CreateLogGroup", "Resource": "arn:aws:logs:ap-northeast-1:xxxxxxxxx:*" }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:ap-northeast-1:xxxxxxx:log-group:/aws/lambda/rds_s3_export:*" ] } ] } |
- files/assume_role_policy/lambda_rds_s3_export.json
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } |
- files/assume_role_policy/rds_s3_export.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "arn:aws:s3:::*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "s3:PutObject*", "s3:GetObject*", "s3:DeleteObject*" ], "Resource": [ "arn:aws:s3:::hoge", "arn:aws:s3:::hoge/*" ] } ] } |
- iam.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
## lambda_rds_s3_export resource "aws_iam_role" "lambda_rds_s3_export" { name = "lambda_rds_s3_export" assume_role_policy = file("files/assume_role_policy/lambda_rds_s3_export.json") } resource "aws_iam_policy" "rds_s3_export" { name = "rds_s3_export" description = "rds_s3_export" policy = file("files/assume_role_policy/rds_s3_export.json") } resource "aws_iam_role_policy_attachment" "lambda_rds_s3_export" { role = aws_iam_role.lambda_rds_s3_export.name policy_arn = aws_iam_policy.rds_s3_export.arn } ## lambda_rds_s3_export_role resource "aws_iam_role" "lambda_rds_s3_export_role" { name = "lambda_rds_s3_export_role" assume_role_policy = file("files/assume_role_policy/lambda.json") } resource "aws_iam_policy" "lambda_rds_s3" { name = "lambda_rds_s3" description = "lambda_rds_s3" policy = file("files/assume_role_policy/lambda_rds_s3.json") } resource "aws_iam_role_policy_attachment" "lambda_rds_s3" { role = aws_iam_role.lambda_rds_s3_export_role.name policy_arn = aws_iam_policy.lambda_rds_s3.arn } resource "aws_iam_policy" "lambda_rds_s3_execution" { name = "lambda_rds_s3_execution" description = "lambda_rds_s3_execution" policy = file("files/assume_role_policy/lambda_rds_s3_execution.json") } resource "aws_iam_role_policy_attachment" "lambda_rds_s3_execution" { role = aws_iam_role.lambda_rds_s3_export_role.name policy_arn = aws_iam_policy.lambda_rds_s3_execution.arn } |
- lambda.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
resource "aws_lambda_function" "rds_s3_export" { description = "rds s3 export" s3_bucket = "hoge" s3_key = "lambda/rds-s3-export.zip" function_name = "rds_s3_export" role = aws_iam_role.lambda_rds_s3_export_role.arn handler = "lambda_function.lambda_handler" runtime = "python3.9" memory_size = "128" timeout = "60" environment { variables = { IAM_ROLE_ARN = aws_iam_role.lambda_rds_s3_export.arn KMS_KEY_ARN = aws_kms_key.hoge.arn S3_BUCKET_NAME = aws_s3_bucket.hoge.bucket } } } |
- lambda-handler.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import os import json import boto3 from datetime import datetime,date,timedelta S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME'] IAM_ROLE_ARN = os.environ['IAM_ROLE_ARN'] KMS_KEY_ARN = os.environ['KMS_KEY_ARN'] client = boto3.client('rds') def lambda_handler(event, context): today = datetime.today() yesterday = today - timedelta(days=1) SOURCE_ARN="arn:aws:rds:ap-northeast-1:xxxxxxxxxx:cluster-snapshot:rds:xxxx-" + datetime.strftime(yesterday, '%Y-%m-%d-xx-xx') EXPORT_TASK_IDENTIFIER="hoge" + datetime.now().strftime("%Y%m%d%H%M%S") response = client.start_export_task( ExportTaskIdentifier=EXPORT_TASK_IDENTIFIER, SourceArn=SOURCE_ARN, S3BucketName=S3_BUCKET_NAME, IamRoleArn=IAM_ROLE_ARN, KmsKeyId=KMS_KEY_ARN, ExportOnly=[ 'hoge', ] ) |
- eventrule.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# rds-s3-export resource "aws_cloudwatch_event_rule" "rds_s3_export" { name = "rds_s3_export" description = "rds_s3_export" schedule_expression = "cron(0 16 ? * * *)" is_enabled = "true" } resource "aws_cloudwatch_event_target" "rds_s3_export" { target_id = "rds_s3_export" arn = aws_lambda_function.rds_s3_export.arn rule = aws_cloudwatch_event_rule.rds_s3_export.name } |
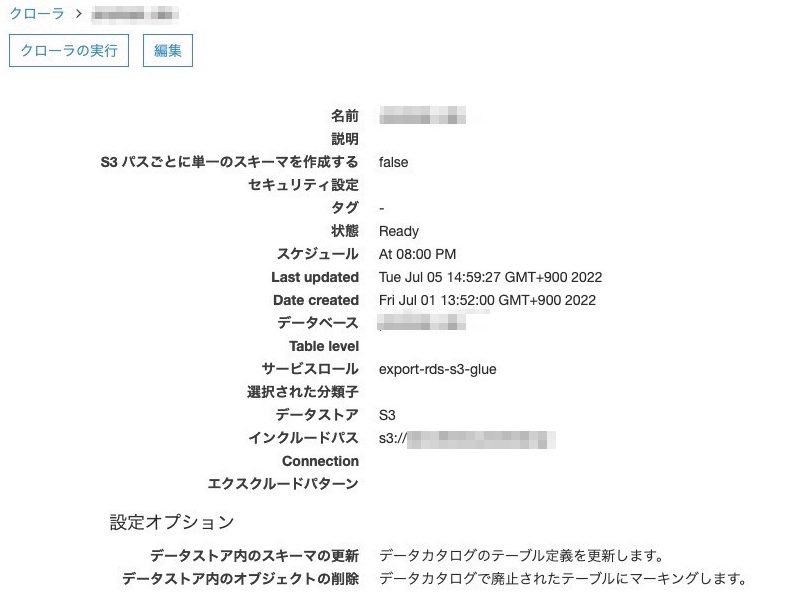
またIAMロールとポリシーまみれですが、Lambdaでは前日分のスナップショットから取得したいテーブルのみに絞りました。EventBridge Ruleで実行できていれば完了となります。しかしこの場合だと日付ごとにテーブル化されてしまうので色々と考慮しないといけないですね。Glueの設定で Crawl new folders only があるのでこれで良さそう。
Crawl new folders only
Only Amazon S3 folders that were added since the last crawl will be crawled. If the schemas are compatible, new partitions will be added to existing tables.最後のクロール以降に追加されたAmazonS3フォルダーのみがクロールされます。スキーマに互換性がある場合、新しいパーティションが既存のテーブルに追加されます。
GlueのTerraformは以下のように追記すればOK。
|
1 2 3 4 5 6 7 8 |
recrawl_policy { recrawl_behavior = "CRAWL_NEW_FOLDERS_ONLY" } schema_change_policy { delete_behavior = "LOG" update_behavior = "LOG" } |
まとめ
この構成を実装するのが大変でIAMロールのポリシー不足でハマりましたが、一度作ってしまえばなんともない感じですね。テーブル追加はLambdaだけ変更してデプロイすれば完了なので、運用工数が下がるのはメリットですね。Digdagのワークフローの部分は Step Functionsを利用すればできそうだけども、また次回のブログで書きたいと思います。
Athenaほとんど触ったことないので、パーティションやら料金のところを確認してみよう。BigQueryと比べるとクエリ速度どのくらい変わるんだろうか…あまりAthenaの事例見たことないような気がする。



0件のコメント