最近Digdagとembulkを勉強してまして、以前、イマイチDiddagについてまったく理解出来ませんでした。この2つは分析基盤(redashやらログ系)でよく使われており、しかも相性がめちゃくちゃいいとのことで簡単に分かりやすくまとめてみました。
■Digdagって何よ?

TreasureData社がOSSで公開しているツールで、依存関係のある複数のタスクを実行するワークフローエンジンです。簡単に言うと、
「ジョブ管理→cron(バッチ)」
と言えばイメージが湧くと思います。
ワークフローエンジンと言えばJenkinsジジイ、Airflow、Luigiなどがありますが、
Digdagはそれらと比べて3つのメリットがあります。
・YAMLでシンプル,学習コストが低い
・High Availability(HA)構成が容易
・分散環境での動作が容易
少しDigdagの設定ファイルを見てみましょう。
・run.dig
https://docs.digdag.io/scheduling_workflow.html
|
1 2 3 4 5 6 7 8 9 10 11 12 |
timezone: Asia/Tokyo schedule: daily>: 03:00:00 _retry: 3 +adachin-sever_access_log: call>: adachin-server_access_log.dig +adachin-server_error_log: call>: adachin-server_error_log.dig |
上記の例では「スケジューラー機能」と呼ばれるもので、アクセスログとエラーログを
毎日3時にDigdagちゃんがタスクを実行してくれます。ちなみにDigdagのコマンドリファレンスは以下で実行ファイルも適当に作ってみました。
https://docs.digdag.io/command_reference.html
・adachin-server_access_log.dig
|
1 2 3 4 5 6 7 8 9 |
_export: s3_target_date: 2018-5-4 bq_target_date: 20180504 _error: sh>: export xxxxxxxxxxxxxxxx +load: sh>: export /usr/local/bin/embulk run -b xxxxxxxxxxxx embulk/config.yml.liquid |
で、embulkを組み合わせると!?
■embulkって何よ?
![]()
これまたTreasureData社がOSSで公開しているツールで、(古橋さん開発)ファイルやデータベースからデータ抽出を行い、別のストレージやデータベースにデータ転送するためのツールです。もちろんYAML!!設定ファイル見てみましょう。
・config.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
in: type: s3 path_prefix: adachin-server/access-log bucket: [バケット名] access_key_id: [アクセスキー] secret_access_key: [シークレットキー] decoders: - {type: gzip} parser: type: jsonl charset: UTF-8 newline: CRLF columns: - {name: "domain", type: "string"} - {name: "time", type: "timestamp", format: "%Y-%m-%dT%H:%M:%S%z"} - {name: "agent", type: "string"} - {name: "status", type: "string"} - {name: "user", type: "string"} filters: - type: add_time to_column: name: time_jst type: timestamp from_column: name: time - type: eval eval_columns: - time_jst: value + (9 * 60 * 60) - type: to_json column: {name: time, type: string} default_format: "%Y-%m-%d %H:%M:%S" out: type: bigquery mode: append auth_method: private_key service_account_email: [サービスアカウント] p12_keyfile: [p12形式鍵の置き場] project: [プロジェクトID] dataset: [dataset名] table: [テーブル名] auto_create_table: true schema_file: digdag/embulk/adachin-server-bq.json |
・adachin-server-bq.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
[ { "name": "domain", "type": "STRING" }, { "name": "time", "type": "TIMESTAMP" }, { "name": "agent", "type": "STRING" }, { "name": "status", "type": "STRING" }, { "name": "session", "type": "STRING" }, { "name": "user", "type": "STRING" } |
S3からアクセスログを抽出してBigQueryに飛ばす(同期)ようなことをしています。bigqueryのテーブルスキーマはjsonで作成し、embulk parserで各カラムにつけた型と合わせるだけです。この実行をDigdagでワークフローしてもらいます。構成図は!?
■redash x fluentd x Digdag x embulk
参考
https://qiita.com/shiozaki/items/f79eecf8e1878aa64a40
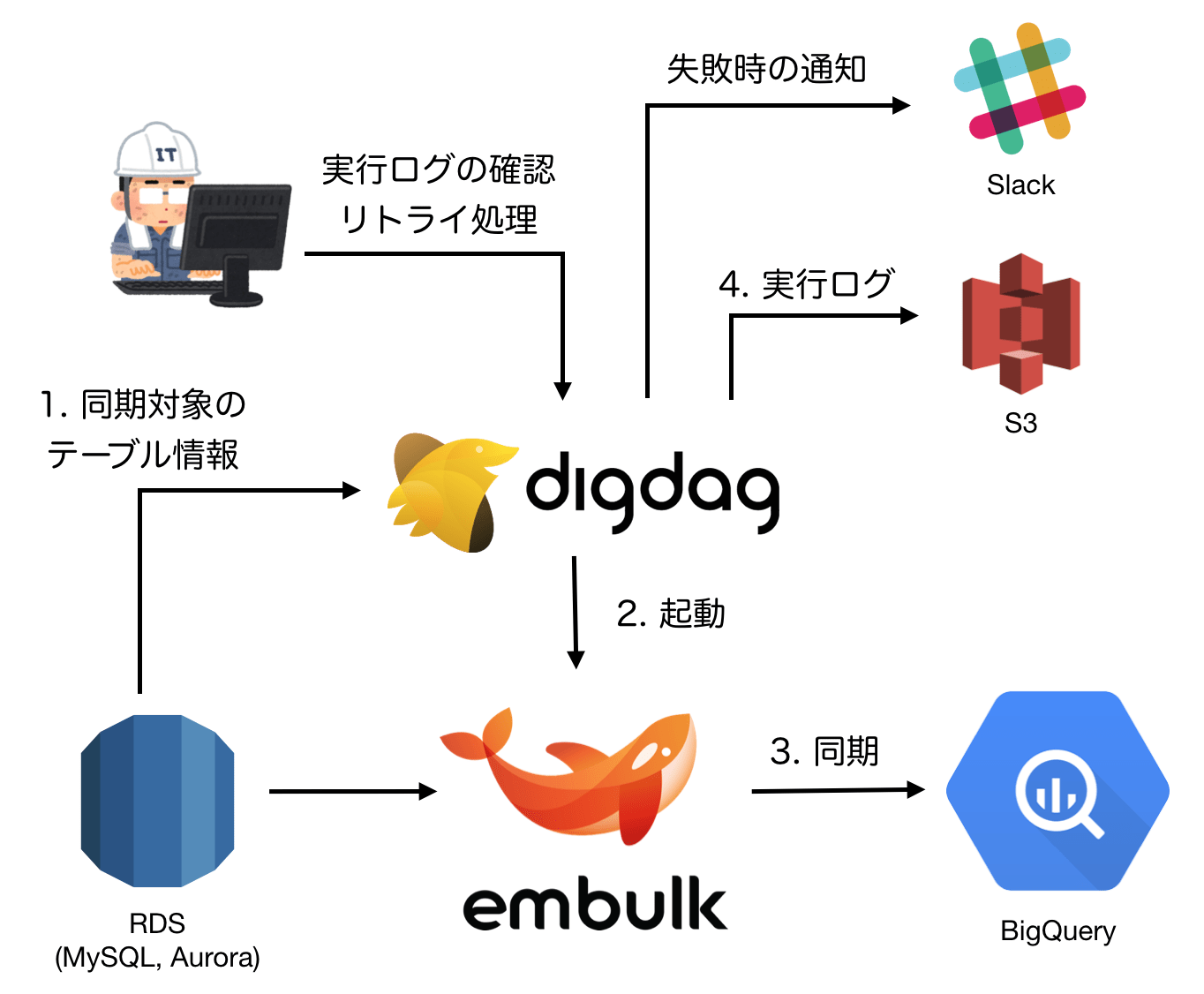
Digdagを使うと、embulkの複数起動を効率的に管理して、データ抽出やら転送がイージーになるわけですな。基本サーバのアクセスログはfluentdを使ってs3に飛ばしましょう。あとはredashがBigQueryの中見ればアクセスログなどの可視化ができる!!!
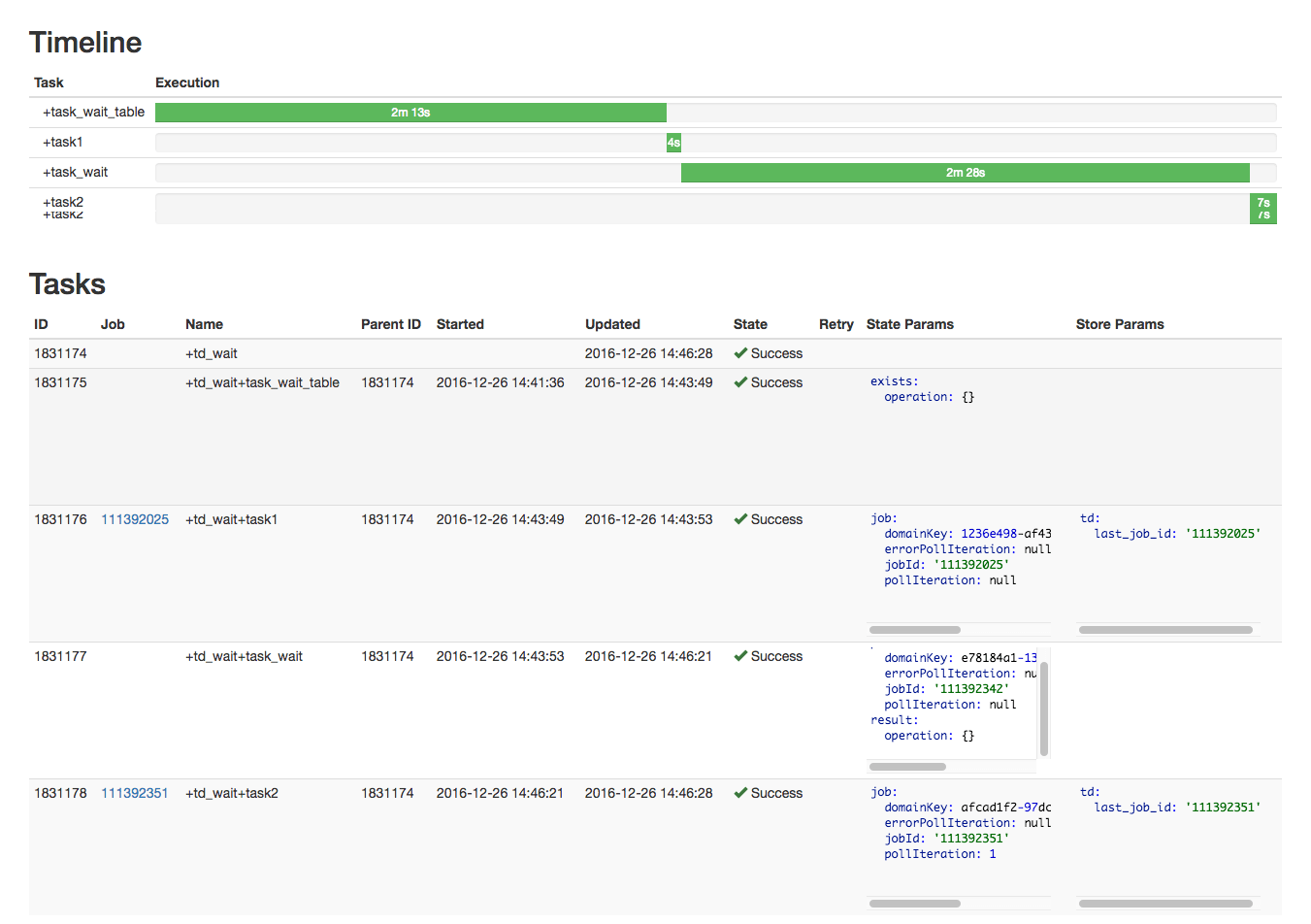
ちなみにDigdagの管理画面ではjobがエラー吐いているのかなども可視化されているので分かりやすい!
参考
https://qiita.com/skryoooo/items/d5c2e092355bd02228c8
■まとめ
分析基盤ならDigdagとembulkで決まりですな。次回はDigdagのコマンドなど徹底して紹介したいと思います!redashはv4に!!!!!!!!
参考
https://qiita.com/nagais/items/47f1cbb117584dbc18c2


0件のコメント