月次で、あるDBをBigQueryに転送したい場合、
実行した年と月をカラムに出力しないといつ実行されたのかわからん!!!!!
そこで以下のようにSQLを叩いてもいいのですが…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 文字列型で取得する場合 > SELECT DATE_FORMAT(NOW(), '%Y%m') as temp; ---------- | temp | ---------- | 201807 | ---------- # 日付型で取得する場合 > SELECT cast('2018-07-01' as DATETIME) as temp; ----------------------- | temp | ----------------------- | 2018-07-01 00:00:00 | ----------------------- |
BigQuery運営していると無駄にSQLが発行されて料金が高くなってしまう恐れがあるので、
embulkで完結できないものかとググっていたら良いプラグインを発見しました!
■embulk-filter-column
https://github.com/sonots/embulk-filter-column
add_columsは下記。

digdagを使っているので、digdagファイルで日付を変数化すればいい感じになる!
■Install embulk-filter-column
|
1 2 3 4 5 6 7 8 9 10 |
$ vim Gemfile source 'https://rubygems.org/' gem 'embulk', '~> x.x.x' ~省略~ gem 'google-cloud-bigquery' gem 'google-cloud-core' gem 'google-cloud-env' gem 'embulk-filter-column' #追加 $ embulk bundle |
基本プラグインはGemfileで管理しやしょう!
■hoge.json
|
1 2 3 4 5 6 7 8 9 10 |
[ { # これ追加な "name": "history_date", "type": "DATE" }, { "name": "id", "type": "INT64" }, ~省略~ |
今回はhistory_dateという名前にして先頭に追加しました。
(結構名前生み出すのが大変)
■hoge.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
in: type: mysql {% if env.EMBULK_ENV == 'prod' %} {% include 'db/prod' %} {% else %} {% include 'db/pre' %} {% endif %} query: | SELECT id,adachin ~省略~ FROM users u INNER JOIN adachin up ON u.id = up.id WHERE ~省略~ column_options: birthday: {type: string, timestamp_format: "%Y-%m-%d"} ## ここから追加 filters: - type: column add_columns: - {name: history_date, type: string , default: {{ env.history_date_value }} } out: type: bigquery mode: replace auth_method: json_key json_keyfile: /config/bq.key {% if env.EMBULK_ENV == 'prod' %} {% include 'db/prod' %} {% else %} {% include 'db/pre' %} {% endif %} auto_create_dataset: true auto_create_table: true dataset: db_snapshot table: hoge_{{ env.bq_target_date }} schema_file: /xxxx/embulk/db/hoge.json open_timeout_sec: 300 send_timeout_sec: 300 read_timeout_sec: 300 auto_create_gcs_bucket: false gcs_bucket: {{ env.EMBULK_OUTPUT_GCS_BUCKET }} compression: GZIP source_format: NEWLINE_DELIMITED_JSON default_timezone: "Asia/Tokyo" |
BigQueryの仕様上データ件数1件でもフルスキャンされて死亡してしまうため、
38行目のtable指定は日付を分割テーブルにしています。
BigQuery分割テーブルについては以下を参考に!
https://cloud.google.com/bigquery/docs/partitioned-tables?hl=ja
■hoge.dig
|
1 2 3 4 5 6 7 8 9 |
_export: bq_target_date: ${moment(session_date).format('YYYYMM01')} history_date_value: ${moment(session_date).format('YYYY-MM-01')} _error: sh>: export $(cat config/env | xargs) && /opt/xxxx/xxxx.sh "[${session_time}][${session_id}] DigDag Fail hogehoge" +hogehoge: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk run -b $EMBULK_BUNDLE_PATH embulk/hoge.yml.liquid |
また日付の変数は上記のように月次の1日に実行するよう表記しています。
■digdag run hoge.dig
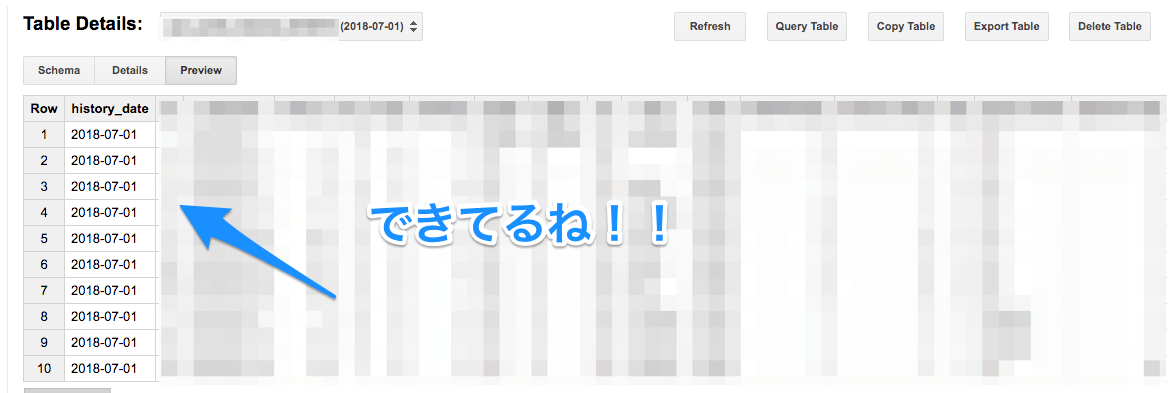
!!!
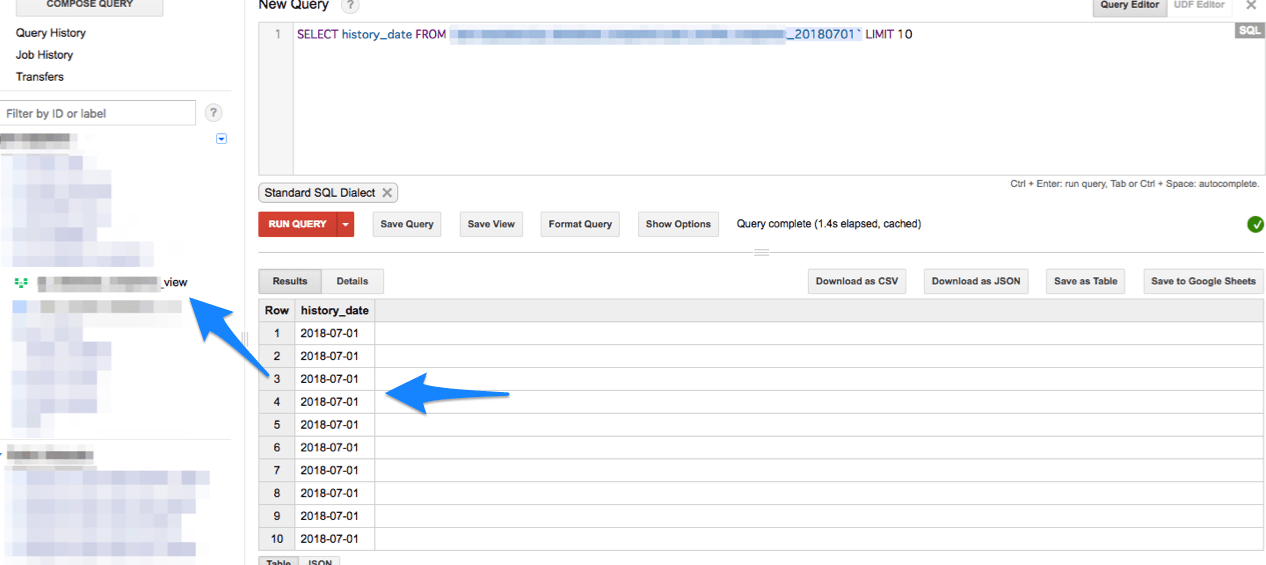
Viewテーブル作って確認してみると、
ちゃんと値取れてるので問題なさそう!!
■まとめ
しかしembulkで書いてテストしてエラー起きての繰り返しで
1日で終わってしまう。。。最近スピード早くなった!!!


0件のコメント