初めてAuroraオートスケールの設定をTerraform化した。
— adachin👾SRE (@adachin0817) February 1, 2022
さて、一時的なアクセス負荷対策としてEC2やECSの台数を増やす以外にも(以下ブログより)、DBもスケールアウトを設定しなければなりません。今回は初めて、TerraformでAmazon Aurora Auto Scalingを設定してみたのでブログします。
Aurora レプリカでの Amazon Aurora Auto Scaling の使用
接続およびワークロード要件を満たすために、Aurora Auto Scaling は、シングルマスターレプリケーションを使用して、Aurora DB クラスター用にプロビジョニングされた Aurora レプリカの数を動的に調整します。Aurora Auto Scaling は、Aurora MySQL と Aurora PostgreSQL の両方で使用できます。Aurora Auto Scaling により、お使いの Aurora DB クラスターは急激な接続やワークロードの増加を処理できます。接続やワークロードが減ると、Aurora Auto Scaling は未使用のプロビジョニングされた DB インスタンスに対する料金が発生しないように、不要な Aurora レプリカを削除します。
Aurora Auto Scaling は、DB クラスターのすべての Aurora レプリカが利用可能な状態にある場合のみ、DB クラスターをスケールします。Aurora レプリカのいずれかが利用可能以外の状態にある場合、Aurora Auto Scaling は DB クラスター全体がスケーリングに利用可能になるまで待機します。
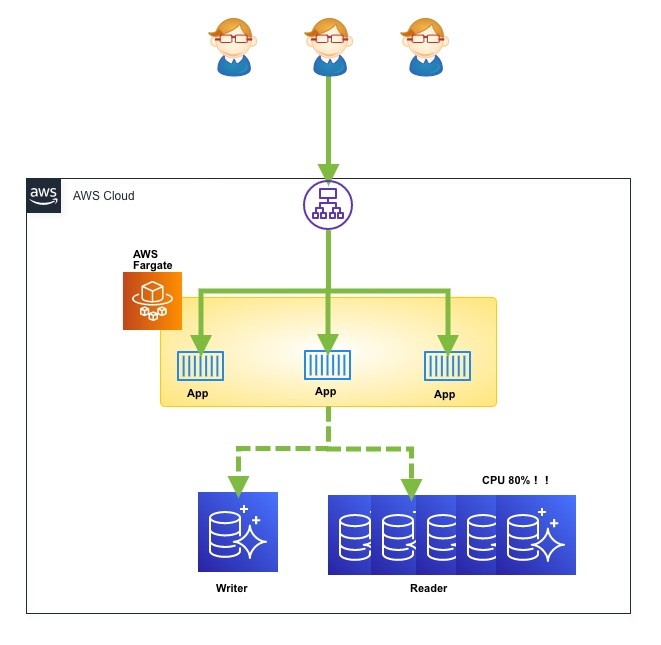
前提としてリードレプリカに対して平均CPU使用率や平均接続数に応じて自動でリードレプリカ台数をスケールアウトすることができます。事前にアプリケーション側で接続設定をread/writeで分けるように設定する必要があります。エンドポイントは必ずクラスターのreadonlyを指定しましょう。
また、Amazon Aurora Auto Scalingを導入することで、急なスパイクアクセスに備えて手動でリードレプリカを作成するなどの運用コストがかからないというメリットもあります。しかしながら、レプリカを増やす時差がありますので502が避けられないのと、CPUの閾値を予め低めに設定すればいいというほど単純ではありません。事前に放映などで分かっているのであれば手動で予め増やしておく運用は避けられないというデメリットもあります。
Terraform
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/appautoscaling_target
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/appautoscaling_policy
- rds.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
resource "aws_appautoscaling_target" "hoge_replicas" { service_namespace = "rds" scalable_dimension = "rds:cluster:ReadReplicaCount" resource_id = "cluster:${aws_rds_cluster.hoge_cluster.id}" min_capacity = 1 max_capacity = 5 } resource "aws_appautoscaling_policy" "hoge_replicas" { name = "hoge-readonly" service_namespace = aws_appautoscaling_target.hoge_replicas.service_namespace scalable_dimension = aws_appautoscaling_target.hoge_replicas.scalable_dimension resource_id = aws_appautoscaling_target.hoge_replicas.resource_id policy_type = "TargetTrackingScaling" target_tracking_scaling_policy_configuration { predefined_metric_specification { predefined_metric_type = "RDSReaderAverageCPUUtilization" } target_value = 80 scale_in_cooldown = 300 scale_out_cooldown = 300 disable_scale_in = true } } |
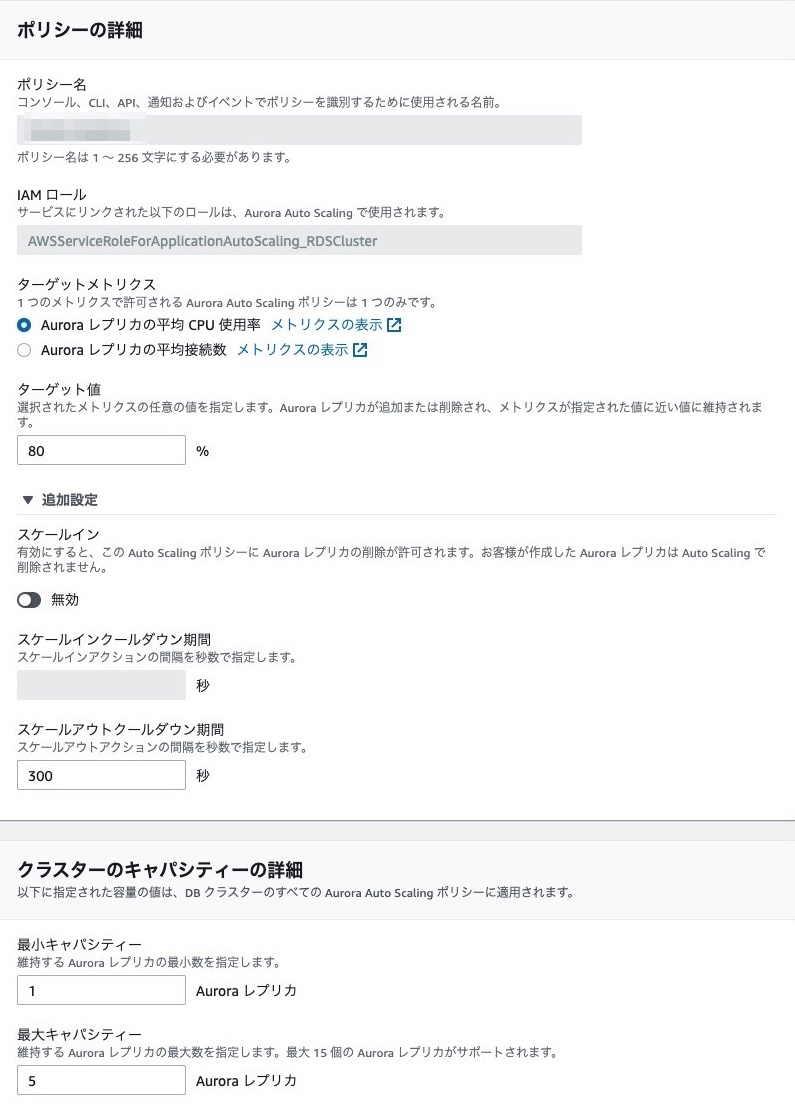
スケーリングポリシーではターゲット値がCPU 80%以上になればリードレプリカが最大5台まで増やすようにしました。また自動でのスケールインは無効化にしていますが、自動削除により、うまく切り替わらずにエラーが出てしまった経験がありました。ですが、2年前だったので現在ではAWS側で修正されているかもしれない!?(以下より)
https://qiita.com/yKanazawa/items/a4342928e78f7ed44e4d
※追記


自動でのスケールイン試してみましたが、リードレプリカ削除中でも問題なくアクセスはできました。 disable_scale_in = false に有効化しても問題なさそうです!
まとめ
導入は非常に簡単だったのと構築時には設定必須だと感じました。が、オートスケール時のリードレプリカの作成が長いので、結局は事前に増やすということも念には念を入れる必要がありそうです。



0件のコメント