はじめに
第11回目のゆるSRE勉強会は、「AI x SREの知見が聞きたい!」というテーマでココナラオフィスで開催されました。むちゃくちゃ勉強になったので、まとめていこうと思う!ゆるくな!
概要
https://yuru-sre.connpass.com/event/353153/
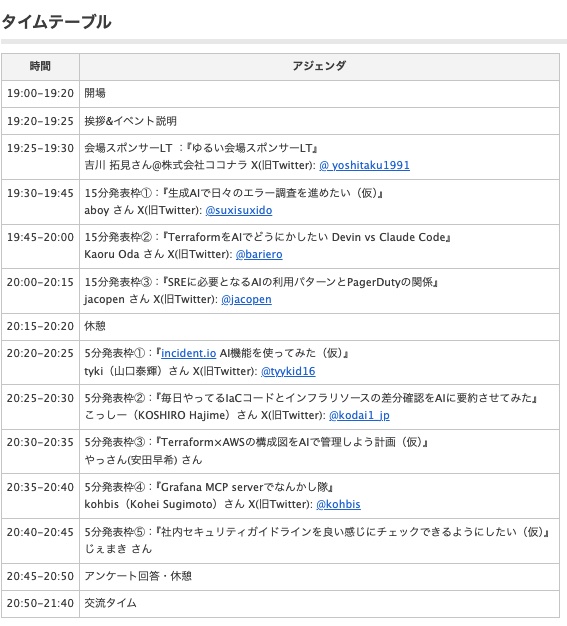
- タイムテーブル
エラー調査を生成AIで進めていきたい
- SRE専門部隊はいないが、SRE夕会を実施してエラーや運用課題を共有
- エラー対応は2種類で運用
- 異常系エラー → プロジェクト単位でSlackに通知(新規/再発時)
- 準正常系エラー → エラー内容ごとに定量監視ルールを設定
- 通知は来ているが、エラーの修正・解決に時間がかかる
- 事業優先でエラー調査が後回しになりやすい
- 原因は分かっていても、根本修正ではなく緩和的な対応が多い
- 生成AIは便利そうだが、活用理解が進んでいない
- 生成AIツール「Devin」を使ってパフォーマンスチューニング支援を試行
- APMで原因が分かっているが、類似実装や改善案までDevinが提案してくれる
- 例:レイテンシーが高いエンドポイントの分析 → 類似処理と比較し根拠付きでアドバイス
- 壁打ち相手としても有用で、ドメイン知識や実装の抜け漏れに気づける
- エラー管理に使っているSentryとGitHubを連携
- 特定のラベルが付いたGitHub IssueをActions経由でDevinに渡す
- Devinが調査結果を返すように自動化
- よく見るエラーや対応済みのものは手順化してAI活用しやすく整備中
- 今後はエラー対応の方針検討などもAIに任せる方向
- SentryとDevinをより細かく連携させて、詳細なエラー分析の自動化を進める
- 生成AIによる障害対応・ナレッジ集約の自動化で、人的対応コストを削減しながら品質向上を目指す
TerraformをAIでどうにかしたい
- EKSアップグレード作業を自動化・効率化するために、生成AIツールの DevinとClaude Codeを比較検証
- 対象はTerraformコードの編集・CI/CD対応・PR作成・Plan/Apply実行など
- CIが失敗しても自動でやり直してくれてコード修正もしてくれる
- Terraformのaddonバージョンの変更は少し怪しいが、修正内容とPRも自動生成してくれる
- Atlantisでのplan実行まで可能、さらにapplyも実行できる
- VMベースで動作するため、ある程度のセットアップが必要
- Lintが通らないコードも生成されることがあり、結果を読み取れないことがある
- コストは約20ドル前後だが、時間かかる作業を代替できるためコスパ良好
- 指示通りTerraform addonのバージョン変更が可能だが、一部しか修正されないケースがある
- PRコメントは Devinよりもやや簡素
- Lint対応済みのコード生成が可能で、CIもスムーズに通過
- terraform planでは AWS認証と-auto-approve の指定が必要だが、そこは自動化されなかった
- Devinと同様にコード変更は可能だが、全体像を理解しないと 設定漏れが発生しやすい
- DevinもClaudeも、コード編集やPR生成はある程度有効だが、使いこなしには注意が必要
- 特にTerraformのようなツールでは「理解して使う」ことが前提条件
- 工数対効果を考えればAI支援の導入は十分に価値あり
SREに必要となるAIの利用パターンとPagerDutyの関係
🚨 インシデント対応フロー × AI活用の可能性
- SREにおけるインシデント対応プロセスの中で、どこにAIが活用できるかをフェーズごとに整理していく
|
フェーズ |
活用の方向性 |
備考 |
|---|---|---|
|
検知 |
オブザーバビリティベンダーがAIで異常を検知 |
Datadogなど各種ベンダーが対応済み |
|
トリアージ |
重要度の高いインシデントを抽出(AIOps向き) |
生成AIだとノイズが多く、AIOpsが有効 |
|
動員 |
ルールベースで対応者のアサイン |
稼働率やスキルに応じた判断が可能 |
|
協力解決 |
LLMが調査・復旧支援(根本原因が明確な場合) |
全自動は難しいが、再現性のある対応には有効 |
|
切り分け |
AIがログや指標から原因の候補を提示 |
人の判断とのハイブリッドが現実的 |
|
コミュニケーション |
Slackのやりとりを要約・共有支援 |
状況共有の質向上、属人化の防止 |
|
ポストモーテム |
LLMでレポート作成の自動化 |
面倒な作業の効率化に効果的 |
|
障害訓練 |
シナリオロールプレイにLLM活用 |
想定シナリオ生成やQ&A形式で支援可能 |
- PagerDuty Agentシリーズ
- Shift Agent
- SRE Agent
- Insight Agent
- すべてをAIに任せるのは現実的ではないが、非常に有効
- 切り分け・報告・共有・訓練など繰り返し性の高い作業では、LLMの導入価値が高い
- 今後は AIが提案・補助する役割を担い、人間が意思決定するという形が主流になる見込み
incident.io AI機能でインシデント対応を省力化する
- インシデント対応後の長文レポート作成は負担が大きい
- AIを活用してレポートやフォローアップ提案の自動化を試みた
- Slackとネイティブ連携できるインシデント管理プラットフォーム
- インシデントの作成からクローズ、改善活動までをSlack上で完結できる
- インシデントクローズ時の自動要約 :レポート作成の手間を軽
- 改善策をSlackで記述、自動的にフォローアップ提案: 継続的な改善アクションが抜け漏れなく記録される
- Raycast拡張でインシデントの提案を補助: サマリーやフォローアップ提案がさらに楽に
- incident.ioは機能追加にも積極的なので、今後の調達・拡張性にも期待大
毎日やってるIaCコードとインフラリソースの差分確認をAIに要約させてみた
💡 背景
- IaCで管理していても、コードと実リソースに差分(ドリフト)が発生する
- 日々の運用でこのドリフト差分の確認は避けて通れない
- Drift Detectorを用いて、インフラとコードの差分を検出
- 差分の内容はSlack およびWeb画面で毎日確認
- 差分が多く、目視では確認がつらい
- terraform planの結果をAmazon Bedrockに入力
- 生成AIが差分を要約してくれるため、重要な変更点にすばやく気付ける
- 特に初心者メンバーでも内容が把握しやすいようになり、チーム内共有もスムーズ
- 毎日のトイルを削減
- 差分内容の理解が容易になり、作業の精度とスピードが向上
- 将来的にさらなる自動化や通知精度向上への期待あり
Terraform x 生成AIで構成図作ってみた
- 構成図の管理は属人化しがちで、手動での更新も多くミスや遅延の原因に
- 社内にはなんと 800個以上の構成図が存在!
- Terraformでインフラ管理していても、構成図の更新は別作業という現実
- TerraformのコードをAmazon Bedrockに入力し、構成図を自動生成する試み
- 最初はプロンプトのチューニングが必要だったが、調整を重ねることで 約90点の構成図が生成可能に
- 将来的には terraform plan の差分結果をAIに与えることで、構成図の自動更新・提案が可能になる構想
- 手動修正の手間を減らし、構成図管理のトイル削減を目指す
- 構成図の自動生成が本格化すれば、ドキュメントと実態の乖離を防げるようになる
- 構成図をAIに任せる未来も、もうすぐそこかも!?
Grafana MCP serverでなんかし隊
- オブザーバビリティ×生成AIで、MCPを活用
- クエリやメトリクスの知識が少なくても、Kubernetesクラスタの調査が可能に
- おうちKubernetesクラスタを対象にGrafana MCP Serverを導入
- MCP Agentが以下を自動で実施
- CPUやメモリの利用状況を分析
- ダッシュボードを一覧化&要約
- 直近7日間の傾向を把握
- Pod数に対しての異常値に気づく
- ローリングアップデート中の挙動も特定
- 実際にその日に作業していた内容と一致 → 高精度な推論結果!
- 原因推定だけでなく、修正案のコード提案まで行う。
- 人手を大幅に減らせる可能性があり、運用負荷の軽減につながる
- MCPの活用で、日常のモニタリング業務をAIで効率化する道が見えてきた
社内の開発ガイドラインに違反していないかLLMでいい感じにチェックしたい
- 開発時のセルフチェックは手間がかかるし、見落としやすい
- 社内ガイドラインの内容が追加・更新されてもチームで追従しきれない
- MCPサーバーを活用して、IaCファイルやアプリコードを自動チェック
- Terraformファイル(.tf)を渡すと
- パスワードの平文記載 → 暗号化推奨
- バックアップ設定の記載漏れ → 指摘
- 適当なRailsアプリを渡すと…
- パスワードは10文字以上などセキュリティベストプラクティスを指摘
- IaCとLLMは相性がよく、チェック精度も高い
- 通常の静的解析で気づきにくいポリシーベースのルールも拾える
- CIへの組み込みも可能で、日常のレビュー品質向上が期待できる
- ガイドラインを自然言語で記述 → LLMで解釈・運用可能な未来が見えてきた
- ルール運用の属人性を減らし、セキュリティ・品質担保を自動化する一歩に
まとめ
AIによってSREやインフラ運用の改善や自動化がますます進化していっていると感じた。すべてをAIに任せられるわけではないものの、調査や構成管理のフォロー、インシデント後のまとめなどトイルの削減には非常に効果的だと感じた。特に構成図の追従は現職でも実装していきたいのと、Devinをバシバシ活用してきたいと思う!
次回のゆるSREはAI失敗事例とかのシェアをしてもらえると盛り上がりそう。とても学びのある会だったのでむちゃくちゃ楽しかったです!ありがとうございました!
NotebookLMで聴きたい方はこちら
https://notebooklm.google.com/notebook/cc0a9ec5-3a8c-428b-95b4-d06aa9e844bf/audio



0件のコメント