今回はembulkでBigQueryのview table(クエリー)をMySQL(Aurora)に飛ばすには
どうしたらいいもんか悩んでいたところ。。
embulk-input-bigqueryという非公式プラグインがあるので試してみました!
他のやり方ではview tableをGCSにexportして、そこからbq cliコマンドやらembulkでMySQLに飛ばす!
というなんとも力技な方法がありますが、さすがにつらたんなので、プラグインが楽かと!とりあえずブログしやす。
■構成
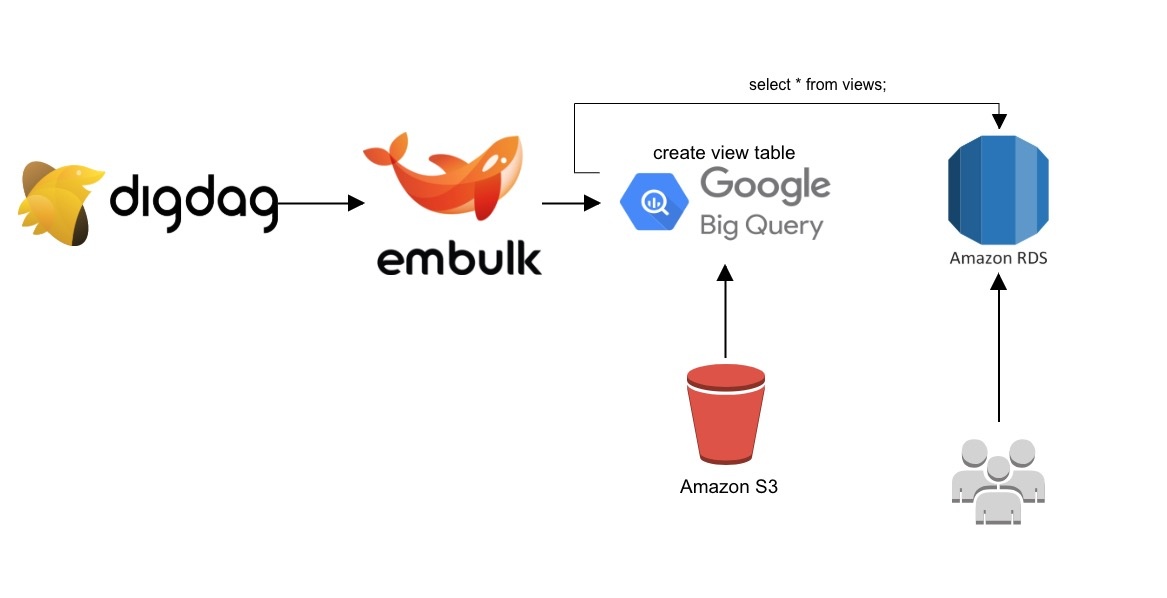
S3のログをBigqueryに集約して、さらにきれいにクエリーでviewで作成し、
embulkでそのクエリーをMySQL(Aurora)に飛ばす!あとはDigdagでスケジューリング!というのをやりたいんですわ。
■medjed/embulk-input-bigquery
https://github.com/medjed/embulk-input-bigquery
■Query Options
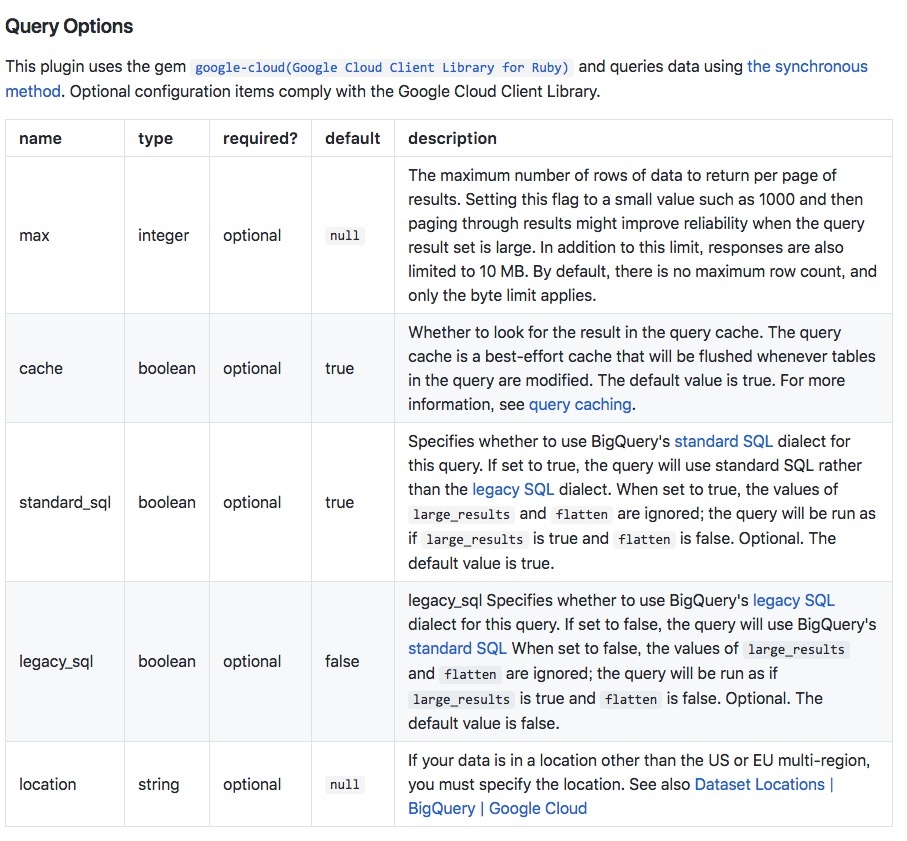
・max(integer)
結果の1ページあたりに返されるデータの最大行数。 1000などの小さな値に設定して結果をページングすると、
クエリ結果セットが大きい場合に信頼性が向上する可能性があります。 この制限に加えて応答も10 MBに制限されています。
デフォルトでは最大行数はなく、バイト数制限のみが適用されます。
ちなみにBiqQueryで検索してCSVでダウンロードしようとしたときに、
容量制限がかかるので注意しないとですな。
https://cloud.google.com/bigquery/exporting-data-from-bigquery?hl=ja
・cache(boolean)
クエリキャッシュ内の結果を検索するかしないか。 クエリキャッシュはクエリ内のテーブルが変更されるたびに
フラッシュされるベストエフォート型キャッシュです。 デフォルト値はtrue。
・standard_sql(boolean)
BigQueryの標準SQL型を使用するかどうかを指定します。 trueに設定するとクエリは従来のSQLではなく標準SQLを使用します。
また、large_resultsとflattenの値は無視されます。 large_resultsがtrueでflattenがfalseであるかのようにクエリが実行されます。デフォルト値はtrue。
BigQueryは独自SQLの書き方があるのですが、(下記より)
最近では標準のMySQLと同じSQLが書けるようになりました。
なのでlegacy_sqlを使って書かなくてOKかと。
・legacy_sql(boolean)
BigQueryのレガシーSQLを使用するかどうかを指定します。 falseに設定するとクエリはBigQueryの標準SQLを使用します。
またlarge_resultsとflattenの値は無視されます。 large_resultsがtrueでflattenがfalseであるかのようにクエリが実行されます。デフォルト値はfalseです。
・location(strong)
データが米国またはEUの複数地域以外の場所にある場合は場所を指定する必要があります。
■Install
|
1 2 3 4 5 6 7 |
$ embulk gem install embulk-input-bigquery 2018-05-21 11:25:46.036 +0900: Embulk v0.8.35 Gem plugin path is: /home/adachin/.embulk/jruby/2.3.0 ~省略~ Successfully installed embulk-input-bigquery-0.0.6 ~ gems installed |
・Gemfile
基本Gemfileでバージョン管理したほうがいいので、以下のようにしましょう。
|
1 2 3 4 5 6 7 8 9 |
source 'https://rubygems.org/' gem 'embulk', '~> 0.8.0' + gem 'embulk-input-bigquery' + gem 'embulk-output-mysql' + gem 'google-api-client', '0.10.1' + gem 'google-cloud-bigquery' + gem 'google-cloud-core' + gem 'google-cloud-env' |
・反映
|
1 |
$ embulk bundle |
■views.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
in: type: bigquery project: {{ env.BIGQUERY_PROJECT }} keyfile: '/digdag/adachin-server_bigguery_to_mysql/config/bq.key' sql: SELECT * ,DATETIME_ADD(CURRENT_DATETIME(), INTERVAL 9 HOUR) as adachintaro,DATETIME_ADD(CURRENT_DATETIME(), INTERVAL 9 HOUR) as adachinsan FROM `{{ env.BIGQUERY_PROJECT }}_views.views` where dt='{{ env.bq_target_date }}' columns: - {name: adachin-dt, type: string} - {name: host-adachin_id, type: string} - {name: adachin, type: string} - {name: adachin_id_view, type: string} - {name: adachintaro_id_view, type: string} - {name: adachintaro, type: string} - {name: adachinsan, type: string} standard_sql: true out: type: stdout |
まずはinputから作っていきます。
とりあえずview tableからsqlでテーブルにある値を標準出力していきましょう。
カラムのdtは日付でtypeをdateにするとembulk側でエラーが出るので一旦stringにしてます。
それとbigquery側は日付がUTCなのでDATETIME_ADDで9時間プラスしてます。
whereでテーブルの日付を指定していますが、digdag run時に特定日付を出力したいためです。
standard_sqlをtrueにしましたがデフォルトがtrueなので書かなくてもOK。
・run embulk
|
1 2 3 4 5 6 7 8 |
$ embulk run views.yml.liquid 2018-06-06 00:05:13.857 +0900: Embulk v0.8.35 2018-06-06 00:05:24.879 +0900 [INFO] (0001:transaction): Loaded plugin embulk-input-bigquery (0.0.6) 2018-06-06 00:05:24.933 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=4 / output tasks 2 = input tasks 1 * 2 2018-06-06 00:05:24.958 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0} 2018-05-30,xxxxxxxxx,1,1,1 2018-05-30,xxxxxxxxx,1,1,1 ~省略~ |
これで値が標準出力できたら次はoutでMySQLに飛ばしましょう!
■embulk/embulk-output-jdbc/embulk-output-mysql
https://github.com/embulk/embulk-output-jdbc/tree/master/embulk-output-mysql
■column_options

・type
新しいセルを作成するときの列の型(VARCHAR(255)、INTEGER NOT NULL UNIQUEなど)
このプラグインが中間テーブル(insert、insert_truncateおよびmergeモード)を作成し、
ターゲットテーブルを作成するとき(insert_direct、merge_direct、およびreplaceモード)、
および存在しないターゲットテーブルを自動的に作成するときに使用されます。
(文字列、デフォルト:入力列の型に依存BIGINT入力列の型が長い場合はブール値、
ブール値の場合はブール値、倍数の場合は倍精度値、文字列の場合はCLOB、タイムスタンプの場合はTIMESTAMP)
・value_type
INSERT文を作成するために、入力列の型(embulk型)をデータベース型に変換します。
このvalue_typeオプションは、INSERTステートメント内の値のタイプを制御します。
(文字列、デフォルト:カラムのSQL型によって異なります)
使用可能な値のオプションは以下のとおりです
byte、short、int、long、double、float、boolean、string、nstring、日付、時刻、タイムスタンプ、10進数、json、null、pass )
・timestamp_format
入力列タイプ(エンブレークタイプ)がタイムスタンプでvalue_typeがstringまたはnstringの場合、
タイムスタンプ値を文字列にフォーマットする必要があります。 このtimestamp_formatオプションは
タイムスタンプのフォーマットを制御するために使用されます。 (文字列、デフォルト:%Y-%m-%d%H:%M:%S.%6N)
・timezone
入力列タイプ(エンブレークタイプ)がタイムスタンプの場合、タイムスタンプ値をSQL文字列にフォーマットする必要があります。
タイムゾーンオプションを使用してタイムゾーンを制御します。 (文字列、default_timezoneオプションの値がデフォルトで使用されます)
■Modes

replaceにするとinputで指定したとおりにテーブルが再作成されるので、ビビらないように!!
基本日付ごとにテーブルへ插入したいのでinsertでOKです。
ちなみにembulk実行時にTRANSACTIONを発行して処理が終わったらcommitをしているので、
エラーなど出てもincertなどは発行されません。
■install
|
1 |
$ embulk gem install embulk-output-mysql |
※こちらも上記のGemfileで管理しましょう!!
■views.yml.liquid
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
in: type: bigquery project: {{ env.BIGQUERY_PROJECT }} keyfile: '/digdag/adachin-server_bigguery_to_mysql/config/bq.key' sql: SELECT * ,DATETIME_ADD(CURRENT_DATETIME(), INTERVAL 9 HOUR) as adachintaro,DATETIME_ADD(CURRENT_DATETIME(), INTERVAL 9 HOUR) as adachinsan FROM `{{ env.BIGQUERY_PROJECT }}_views.views` where dt='{{ env.bq_target_date }}' columns: - {name: adachin-dt, type: string} - {name: host-adachin_id, type: string} - {name: adachin, type: string} - {name: adachin_id_uu_view, type: string} - {name: adachintaro_id_uu_view, type: string} standard_sql: true #out: # type: stdout out: type: mysql mode: insert host: {{ env.MYSQL_HOST }} user: {{ env.MYSQL_USER }} port: {{ env.MYSQL_PORT }} password: {{ env.MYSQL_PASS }} database: {{ env.MYSQL_DATABASE }} table: views options: {connectTimeout: 20000} column_options: dt: {value_type: string, timestamp_format: '%Y-%m-%d' } host-adachin_id: {type: 'int'} adachin: {type: 'int'} adachin_id_view: {type: 'int'} adachintaro_id_view: {type: 'int'} adachintaro: {value_type: string, timestamp_format: '%Y-%m-%d %h:%i:%s' } adachinsan: {value_type: string, timestamp_format: '%Y-%m-%d %h:%i:%s' } |
先程作成した設定ファイルにoutとしてMySQLの制御を追加します。
dateの部分はtimestampでフォーマット指定しないと入らないという..
ちなみにテーブルのフォーマットではExtraにauto_incrementを指定しています。
これでembulk runできたら成功です!
・auto_increment
カラムに値が指定されなかった場合、MySQLが自動的に値を割り当てる
データ型は整数で値は1ずつ増加して連番になる
・desc views
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> desc views; +--------------------+------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------------+------------+------+-----+---------+----------------+ | adachin-id | bigint(20) | NO | PRI | NULL | auto_increment | | dt | date | NO | | NULL | | | host-adachin-_id | int(11) | NO | MUL | NULL | | | adachin | int(11) | NO | | 0 | | | adachin_id_view | int(11) | NO | | 0 | | | adachintaro_id_view| int(11) | NO | | 0 | | | adachintato | datetime | NO | | NULL | | | adachinsan | datetime | NO | | NULL | | +--------------------+------------+------+-----+---------+----------------+ |
・see views
|
1 2 3 4 5 6 |
mysql> select * from views limit 50; +------------+------------+-----------------+---------+-----------------+---------------------+------------------------+---------------------+ | adachin-id | dt | host-adachin_id | adachin | adachin_id_view | adachintaro_id_view | adachintaro | adachinsan | +------------+------------+-----------------+---------+-----------------+---------------------+------------------------+---------------------+ | 1 | 2018-05-30 | xxxxxx | 1 | 1 | 1 | 2018-06-06 09:47:18 | 2018-06-06 09:47:18 | | 2 | 2018-05-30 | xxxxxx | 1 | 1 | 1 | 2018-06-06 09:47:18 | 2018-06-06 09:47:18 | |
■Digdag
・run.dig
|
1 2 3 4 5 6 7 8 9 |
timezone: Asia/Tokyo schedule: daily>: xx:xx:xx _retry: 3 +views: call>: views.dig |
・views.dig
|
1 2 3 4 5 6 7 8 |
_export: bq_target_date: ${moment(session_date).subtract(1,'days').format('YYYY-MM-DD')} _error: sh>: export $(cat config/env | xargs) && /digdag/xxxxxx.sh "[${session_time}][${session_id}] DigDag Fail views" +load: sh>: export $(cat config/env | xargs) && /usr/local/bin/embulk -b $EMBULK_BUNDLE_PATH run embulk/views.yml.liquid |
・過去ログ投入スクリプト
https://gist.github.com/RVIRUS0817/1213b22ad8a77c17cea19053bc5ac90d
これでDigdagにスケジューリングすればOK!
■まとめ
ブログ長くなってもうた。。ドキュメント理解するのが難しい….
BigQueryの仕様理解してないとだめですな〜。
とりあえずレコメンド機能の一部として実現できました。
次はデータ消して入れ直す作業が。。。



0件のコメント