お申し込み100名超えました🎉@kazeburo さん、 @isaoshimizu さんをお招きして普段実践している技術やトレンドをお話いただきます✨
kazeburoさんとShimizuさんに聞く、SREに必要なスキルと運用の秘訣 https://t.co/LXd5zd4cc9 #SRE_findy
— まっきーㅣFindy広報・DevRel (@ayamakkie) January 23, 2023
わーい!ブログ楽しみにしてます!!!
— まっきーㅣFindy広報・DevRel (@ayamakkie) February 7, 2023
さて、久しぶりのブログとなります。皆さんお元気ですか!?私は最近DBを触っておりまして、ALTER文を流しまくり地獄で疲労し、久しぶりに顔が真っ青になりました…
今回はFindyの広報まっきー(@ayamakkie)と仲良くさせてもらっている中、SREのキャリア勉強会を紹介してもらいました。そこで、SRE先人のお二人からさくらインターネットの@kazeburoさん、MIXIの@isaoshimizuさんに現場のお話を聞きましたので、イベントレポートします。
イベント概要
https://findy.connpass.com/event/272129/

オープニング・ご挨拶

- アイスブレイク
- 取り組み事例を厚めにお話していく
- 登壇者の紹介
- @kazeburoさん
- さくらインターネット
- 大学卒業から京都のスタートアップにjoin
- MIXIの運用もやっていた
- 2020年〜さくらにjoin

- @isaoshimizuさん
- MIXIみてね事業部 SREマネージャー
- SIerから12年前にMIXIにJOIN
- モンストのSREを経てマネージャーへ

- Findy @ma3tkさん
- CTO佐藤さん
- インフラ経験は片手間で行っている
- SREはまだいない
- お二人に色々聞きたい!!

SREとは
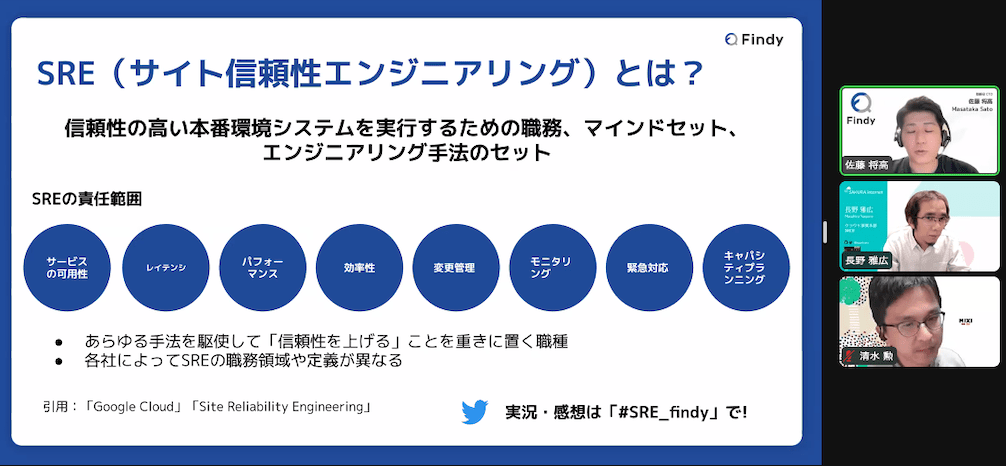
- サイト信頼性エンジニアリングとは
- 信頼性の高い本番環境システム自分を実行するための職務
- マインドセット
- エンジニアリング手法のセット
- SREの責務範囲
- 多いので画像を見てくれ!
- 各社によってどこまで行っているのか聞きたいところ
LT


- さくらインターネットのサービスすべて扱っている
- その中にSRE室がある
- なぜSRE室を作ったのか
- SREとして全社で行っていたのか
- 大きな障害
- 障害の防止をメトリクスとして作成
- より会社全体で評価されるように7月から開始
- 5名で回している
- ミッション
- すべてのクラウドサービスの信頼性を高めてDXをしっかり支える
- ビジョン
- 社内でのSREの実践を広め、お客様の価値提供を行う
- 具体的にどんなことをしているのか
- Embedded SRE
- 開発チームの中で一緒に改善している
- CI/CD、監視、DX向上の仕組みの構築
- SRE as a Serviceの開発
- 社内におけるk8s基盤構築
- ログ/監視基盤の研究開発
- Embedded SRE
- 一緒に手を動かして信頼性の向上文化を作る
- SRE室が多くのサービスの隅々まで信頼性を高めることはできない
- 手を動かして取り組む
- 期待値のズレを防ぐ
- 密なコミュニケーションを行う
- You built it , you run it
- 運用からのフィードバックを受けられる開発をすること
- 運用性の高いソフトウェアを書く
- エンジニアがより良い環境を目指している

- MIXの歴史から
- 2016年モンストのSRE組織が誕生
- 2018年みてねのSREが誕生
- 手探り感で仕組みを作った
- みてね
- DEV
- Rails
- デプロイ
- Schemaの変更
- Feature Toggleの運用
- New Relicでのモニタリング
- BigQuey/Athena/Redash
- SRE
- ミッション
- 安心に使えるサービスを提供
- 組織全体が解決できるように提供
- インフラコストを最適化
- ミッション
- 普段やっていること
- k8s、Terraform
- モニタリング
- アプリケーションモニタリング、ログ分析
- セキュリティリスクの軽減
- アプリケーションのチューニング
- ポストモーテムの作成
- インフラコストの最適化
- DEV
- 質問
- SREチーム二名での工夫は?
- やっていることが異なる
- 共有していないとバラバラ
- 月水金で共有
- レビューはみんなで
- 問い合わせは複数人
- 得意分野があるとその人に偏ってしまう
- なるべく細かいタスクに分ける
- 不得意な人でもできる人からサポートしてもらう
- SREの幅広い知識必要だけど実際どうなのか?
- 一気に身につけられるものではない
- サービスの課題を一つずつ見つけながらやっていく
- 得意不得意ある
- とにかくやってみるペアプロしてみる
- 関係性を作っていく
- SREチーム二名での工夫は?
普段実践している技術は?

- @kazeburoさん
- メインはGo
- Mackerelの開発やってる
- シングルバイナリで簡単にデプロイできる
- 並行処理が簡単に
- Perl/PHP
- DNS、HAProxyなどのミドルウェア
- メインはGo
- @isaoshimizuさん
- Ruby
- EKS
- モニタリング
- クエリのチューニング、コードの修正
- エンコーダのパラメーターチューニング
- 海外ユーザー向けマルチリージョン戦略
- IaC(Terraform)
注目しているトレンドは?

- @kazeburoさん
- Four Keys
- 開発力を上げるためには
- eBPF/XDP
- ロードバランサの拡張
- DNSのDDoSk耐性
- WireGuard
- Four Keys
- @isaoshimizuさん
- NewSQL
- 自動的にシャーディングしてくれるDBに注目
- オブザーバビリティ全般
- k8sにおけるネットワーク
- セキュリティ周りのオブザーバビリティ
- eBPF、Cilium
- NewSQL
- 質問
- 技術選択はどうやって決まるの?
- 自分たちでやっていかなければならない
- 既存のサービスをどうにかしていかない
- 支える課題を開発力をアゲていく
- シャーディングの背景
- みてねはDBがサービスが大きくなればなるほど手作業でシャーディングするのはきつい
- 運用面からみて楽になりそう
- オブザーバビリティ
- まだまだやれるところ改善できるところは無限に出てくる
- Embeddedの運用に巻き込まれるけどどうなの?
- やらないとわからないのでチャレンジ
- 撤退は今の所ない
- みてねは現状導入していない
- 結局運用ばっかしかやっていないので逆に知りたいw
- フェーズとしては自動化なりお客様に提供することで解決して合わせていく
- SREの人材の関わり方について
- SREが必要になるフェーズとしてはインフラが盛り上がる時
- 整っていないときに導入
- サービスを立ち上がるフェーズとしては最初から作っておくのが良さそう
- アプリケーション、インフラ強いひとがバランス良くあるべき
- 最初からそういうメンバーがいると強い
- 初期でアプリケーションチューニング、インフラのチューニング
- プラットフォームを作るフェーズになる
- 最初は全部できたほうがいい
- ログ分析基盤はどういうものを見ているのか
- 仮想サーバーの後ろ側
- どのサーバー、どのストレージなのか基盤を作っているためそのログを知る
- 技術選択はどうやって決まるの?
どうやったらSREになれるのか?

- @kazeburoさん
- 監視をする
- サービスを好きになる
- なぜうまく動かないを突き詰める
- ISUCONに参加する
- @isaoshimizuさん
- 開発者の気持ちになる
- 推測しない、楽観視しない(推測するな!計測せよ!)
- 失敗から学ぶ。その文化を広める
- インフラエンジニアからSREにロールチェンジに必要なスキルとは?
- コードを書く力と読む力は必要
- ソフトウェアに興味を持つ
- 挙動がおかしいときはどこまで把握できるか
- チャレンジ大事
- SREのスキルを持ったエンジニアを育てていくには?
- 運用中に画面共有で一緒にやっていってお互いにスキルアップしていく
Q&A

- SREを導入し始める場合何からすすめるべきか?
- SLI/SLO
- 何をSLIにするのか課題でその後の運用が難しい
- 課題ベースで考えていけばいい
- サービスのレベルどこまで行うのか
- 考えただけ無駄ということも
- ガチガチにやりすぎて厳しい
- SLI/SLO
- インフラ、アプリチームとの境界線は?
- 境界線はある
- Dev、SREの役割の通り
- 基盤チーム データセンター行く
- クラウドのAPIはアプリチーム
- 一緒にコードを書いていくのでオーバーラップして解決していく
- どのようにSREチームとしてインフラを改善していくのか
- 事業にとってのインパクト
- このまま放置すると大ダメージの予測から最優先で行う
- 定期的にモニタリングする
- 毎朝5分でメトリックスのダッシュボードを見る
- そこからタスク化していく
- 課題整理整頓
- 苦労したこと、大変だったこと
- VMからコンテナへ
- 大きく変えるのはハードルが高い
- SREの立ち上げで事業本部に説明をした
- 組織のSREが必要だった場合何から始めるのか
- 監視、モニタリング
- SLI/SLO
- ログ、メトリックス
- 見たくないけど見よう
- 全部やりましょうは良くない
- 必要な部分だけ
- SLI/SLO
- 監視、モニタリング
まとめ
今話題の本が届いた!思っていたよりデカい! pic.twitter.com/5cA1NkqvPI
— adachin👾SRE (@adachin0817) June 12, 2022
お二人のお話を聞いて、個人的にはSREとして経験してきたことは体現できていそうと感じました。振り返ると、SREチーム内での取り組みはその中で完結しまいがちになってしまうのと、他のチームで協力して取り組んでいるというのを全社で伝える必要があるということ。また、自分はコードを読む力よりも書ける力を増やさなければならないということを改めて実感しました。
このイベントを通してSREとして今やるべきことが見えてきたので、なかなか痺れました。早速明日から少しずつ取り組んで行こうと思います。ありがとうございました!
それでは!また!
ちなみにWebパフォーマンスチューニングは@kazeburoさんが書かれてるので皆さん読みましょう〜!
おおおお….🙏 pic.twitter.com/0lK4maASA1
— adachin👾SRE (@adachin0817) February 7, 2023



0件のコメント