そして今日はこのあと19時からこちらのイベントやります✨
Datadog社とSongmuさんに聞く。迅速な顧客価値提供のための監視とオブザーバビリティ https://t.co/Pgx2a8XgC4 #o11y_findy
— まっきーㅣFindy広報・DevRel (@ayamakkie) February 21, 2023
https://t.co/DqUlXofHqt
今日はこちらに参加します!イベントレポートももちろん書きます💪— adachin👾SRE (@adachin0817) February 21, 2023
さて、今回はFindyで初心者向けObservability(可観測性)のイベントに参加してきました。10年前からインフラエンジニア/SREを経験している自分にとっては当時、NagiosやZabbixでインフラのリソースモニタリングをしていくことが多く、次第にアプリケーションのモニタリング(APM)も見ていくことが当たり前になってきました。また、Observabilityによって、よりシステム内部の状態をどれだけよく把握できているのか測定し、サービスの質を担保するのが我々エンジニアの使命であるように変化していきました。それでは先人である、Datadog社の@taiponrockさんと、@songmuさんのお話を聞いてきたのでブログします。
ちなみに前回は「kazeburoさんとShimizuさんに聞く、SREに必要なスキルと運用の秘訣について」イベントレポートまとめておりますので、参考に!
[2023/02/07][Findy]kazeburoさんとShimizuさんに聞く、SREに必要なスキルと運用の秘訣について参加してきた
イベント概要
https://findy.connpass.com/event/273818/

オープニング・ご挨拶

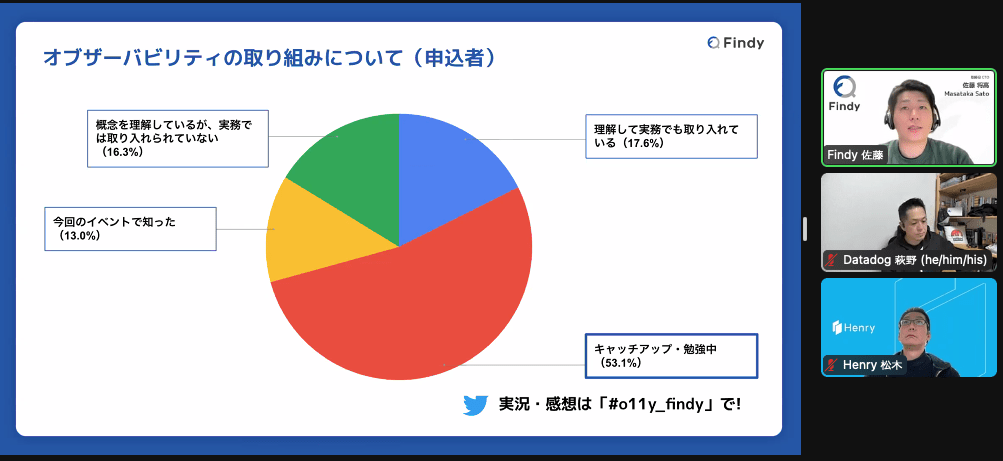
- アイスブレイク
- オブザーバビリティの定義と計測するもの
- オブザーバビリティの第一歩
- o11yの今後
- キャッチアップ・勉強中が多い!
- 自己紹介
- 萩野Taijiさん @taiponrock
- 元々バックエンドからDevRelにシフトしてDatadog社でSenior Technical Advocate

- 松木さん @songmu
- 主にバックエンド
- はてなでMackerel開発
- 「入門監視」著者
- 現在は株式会社ヘンリーでチーフエンジニア

- Findy CTO佐藤さん @ma3tk
- いつもありがとうございます!

Datadog社より「Observability/Datadog 101」

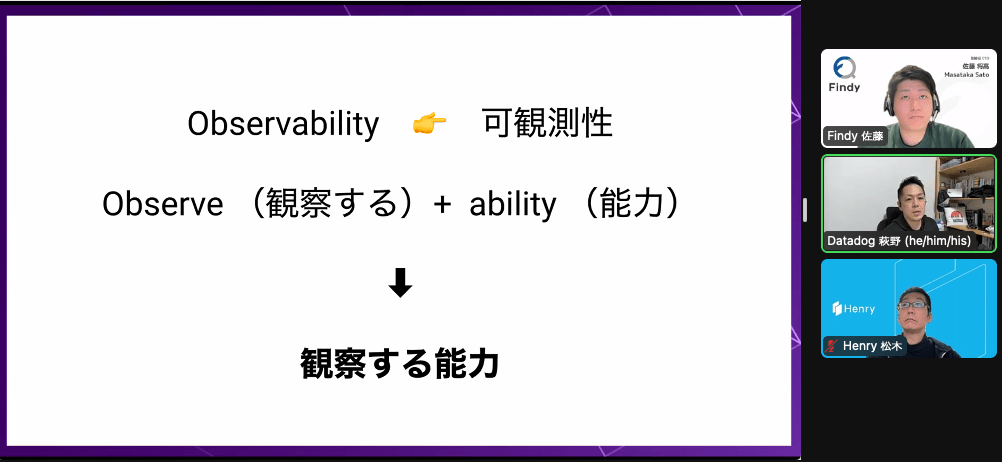
- 萩野Taijiさん @taiponrock
- Observability 可観測性
- 観察する能力
- Observability 可観測性
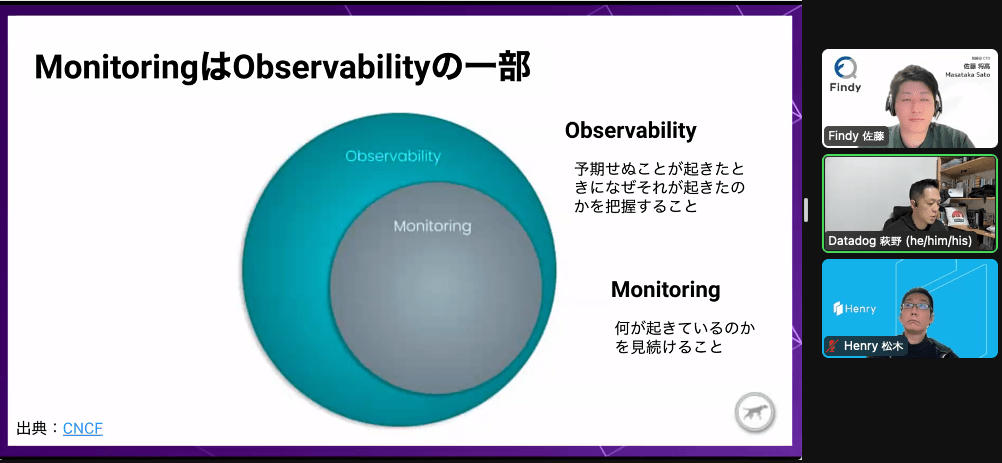
- モニタリングとオブザーバビリティ何が違うのか
- Observability 予期せぬことが起きたときになぜそれが起きたのか把握
- Monitoring 何が起きているのかを見続けること
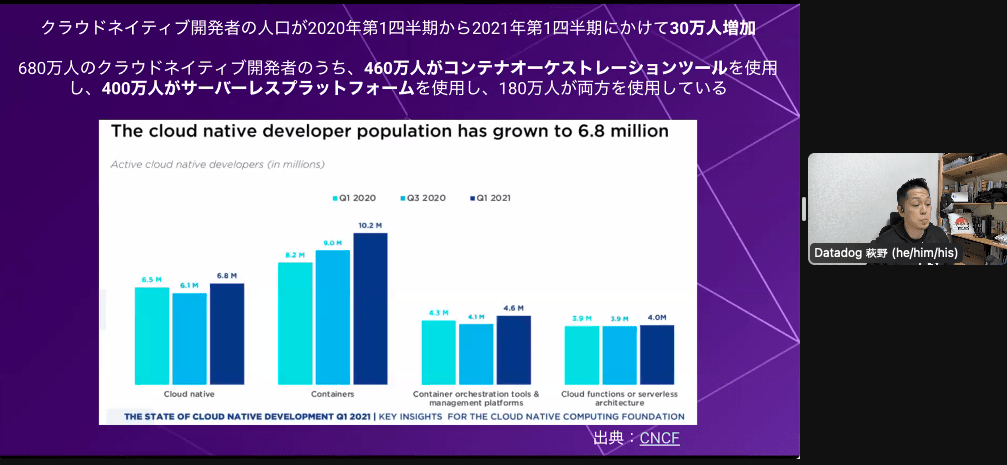
- 時代はCloud Nativeへ
- クラウドネイティブ開発者のは2020→2021年で30万人増加
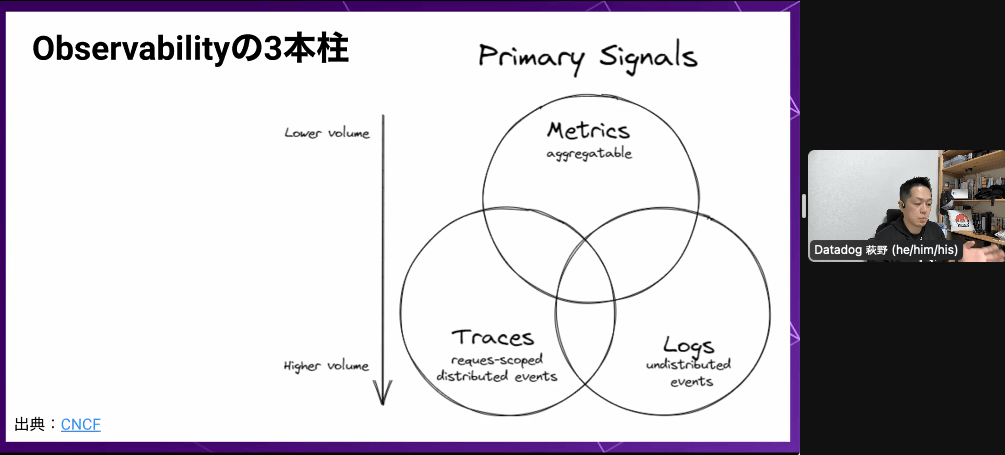
- 三本柱(Metrics,Traces,Logs)
- 取ってくるログ、ソフトウェアの処理をトレーシングしていく
- どこで何が起きているのか
- メトリックス、ログ
- 詳細を追うことができないので難しい
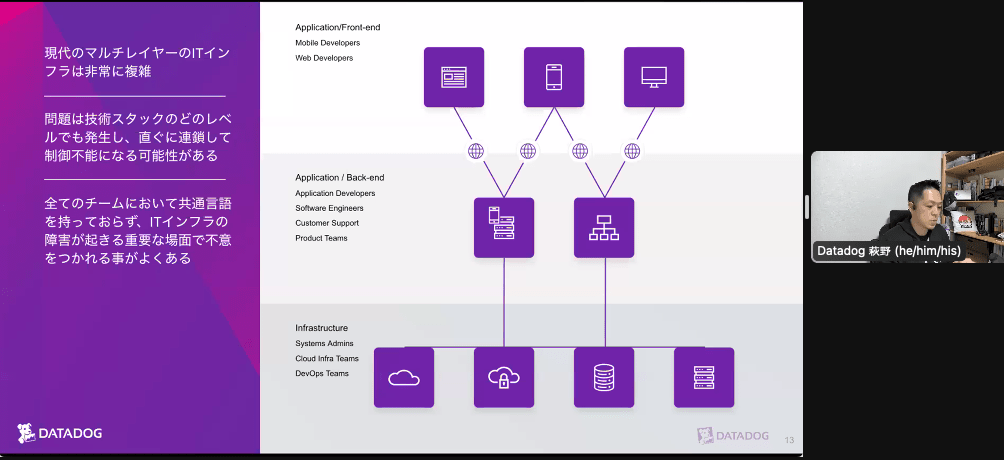
- ログを見ていくと、コアにわかるが、データの量が多い
- 工夫が必要
- フロントエンドのUXモニタリング
- バックエンドの紐付けが難しい
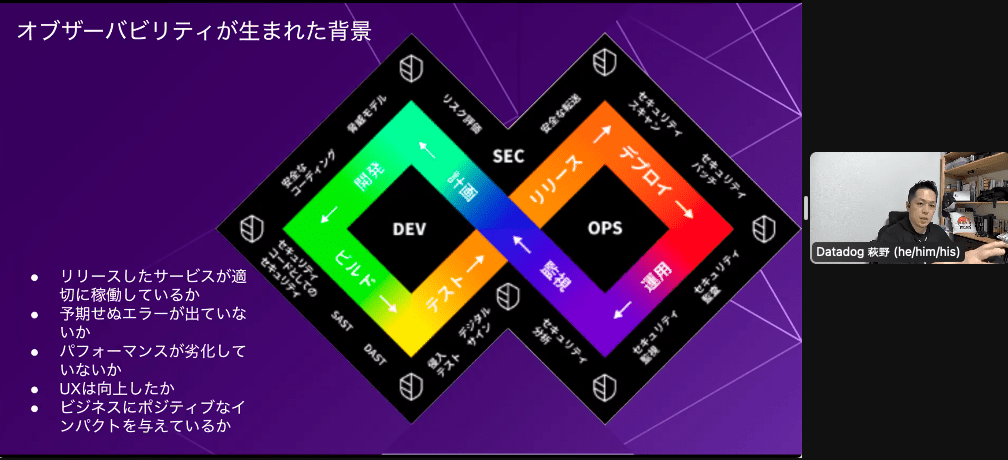
- どこからでも問題特定する仕組みが必要
- シームレスに回していく
- お互いの利害関係でも協力関係含めてサービスが止まらずにしていく

- なぜDatadogを使うのか
- インフラ周り
- 外形監視
- セキュリティのツールから処理が問題なく動いているか
- ソフトウェアデリバリー CI/CDの情報デプロイのトレースをいち早く検知
- ワンプラットフォームで提供している
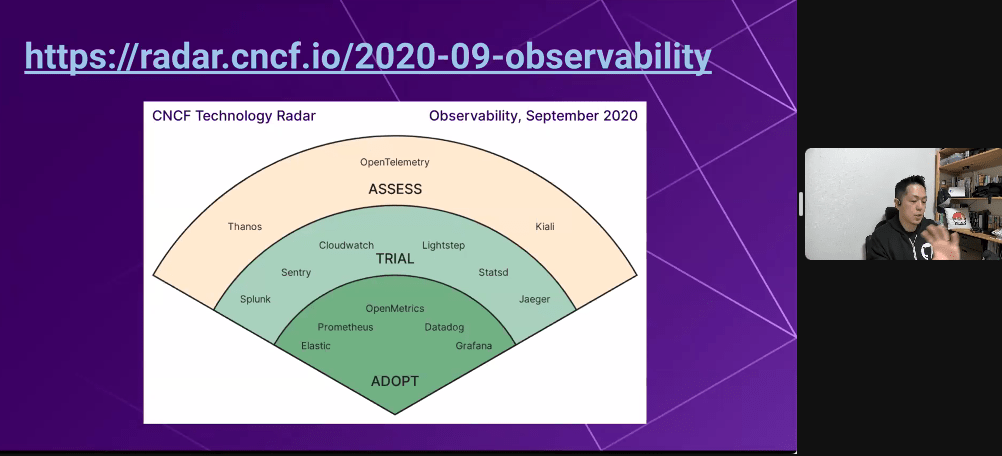
- ASEESS/TRIAL/ADOPT
- バラバラの情報を全部意味のある繋がりを持っていく
オブザーバビリティの定義(監視との違い)と計測する指標について

- 松木さん @songmu
- 011yの定義
- ソフトウェアサービスの開発手法が変わっている
- オンプレからクラウドへ
- スローガン的にオブザーバビリティを作っていく
- ウォータフォールとして悪者と言われてるが
- モニタリング
- 問題調査をどう改善するか
- モニタリングが否定されている
- 凝視する
- 一点を常に見てもしょうがない
- LAMP構成はわかりやすい
- マイクロサービス、コンテナになると複雑化して把握し難い
- 何を指標にするか
- 情報をしっかり集めていく
- データを監視だけでなく分析もしましょう
- テスタビリティをあげていく
- テレメトリ情報の収集
- 同じ調査と障害を対応していくのがオブザーバビリティ

- 萩野Taijiさん @taiponrock
- 向かっている結論に近い
- 今まではエンタプライズシステムの設計がシンプルだった
- 今はクラウドが当たり前になり、マイクロサービスも出てきた
- サーバーレス、コンテナの普及
- アプリケーション開発者はインフラ周り把握しづらい
- 裏では常に最適なリソースを持ってくる
- 動的になるので、複雑化したアプリケーションを動かす現代のアーキテクチャをどのように追従していくのかが鬼門
- 運用と開発に対して、計測はいつ誰が何をするのかが変わっている
- みんなが独自の視点から問題特定に解決していく
- 向かっている結論に近い

- Findy CTO佐藤さん
- 抽象的になりそう
- ベストが決まっていない
- 動的に変化していく難しさ
- 具体的にどんなところを意識するか
- 松木さん @songmu
- SLOを計測するのが基本になっていく
- 可用性やレイテンシー
- 正常レスポンスが何%なのか
- 定義して計測してく
- 調査できる状況が第一歩
- テレメトリをとにかく収集
- 構造化イベントログ
- 一つ一つのイベントをトレースしていく
- 出し続けることによってクエリできる
- そのまま可視化ができる
- オープンテレメトリから意識的に出していく
- まずは第一歩
- Four Keysでも対象になった
- 開発サイクルの中でどこが滞っているか確認する
- SLOを計測するのが基本になっていく
「質問過去に追っていた指標はあるのか」
- JVMのGCログをロギングして可視化している
- 構造的なログをアラートを出している
- 自分たちに必要なログを出していく
- SLI/SLO
- 外形監視
- サービスのパフォーマンスの劣化に気づくこと
- 外側からのドリルダウンから見ていくこと
- SLI/SLO
オブザーバビリティの第一歩

- 松木さん @songmu
- 迅速な顧客価値提供
- それまでのメトリックスなどはやることは変わらない
- 中の情報がわからないと、サービスが止まってしまう
- OpenTelemetryを計装していく
- 迅速な顧客価値提供
- 萩野Taijiさん @taiponrock
- ブロックチェーンの経験があった
- オブザーバビリティという言葉にとらわれる必要はない
- どこからいつ始めるというよりは身近な課題から入っていく
- 単純なインフラの監視
- APMでのテレメトリ
- 自分が何をしたいのか見極めて
- オープンソースで事足りるかもしれない
- Datadogを一部使ってもいい
- アプローチをしていく
- トレンドだからではなく概念を理解していく
「質問オブザーバビリティが目的ではないが大事なポイントとは」
- 松木さん @songmu
- 入門監視の頃にオブザーバビリティが使われるようになった
- 監視やモニタリングの捉え方が変わっていった
- 健全性、信頼性を自分事化していく
- 抽象的な話になりやすい
- 障害対応はエスパー力になりがちになるのでやめよう
- 計測しよう
- 入門監視の頃にオブザーバビリティが使われるようになった
- 萩野Taijiさん @taiponrock
- オブザーバビリティのアプローチ
- バラバラに存在しているデータに対してカンに頼ることが多い
- それに止まってしまう
- 関連付けて意味のあるデータにしていく
- オブザーバビリティのアプローチ
o11yの今後

- 萩野Taijiさん @taiponrock
- AIをどこまで有効的に活用できるかに注目する
- AIを信頼していくと自分たちが勘違いしてしまうことがある
- ツールのベンダー先としては改善していく
- 膨大なログ、細分化されたトレース
- どのように効率的に関連付けていくか
- オブザーバビリティはあくまで手段
- 健全性を保つこと
- ビジネスを止めないこと
- AIをどこまで有効的に活用できるかに注目する
- Songmu @songmu
- オブザーバビリティの概念は定着してるが、プラクティスやエコシステムが定まっていない
- OpenTelemetryエコシステムや関連リリューションの成熟に期待
- 構造化ログを出していく、親子関係をトレースしていく
- みんなで同じものを使う
- 安価に監視していく
- データ量・サンプリング・料金
- 標準フォーマット
- AI活用
- エコシステム
- オブザーバビリティというものに対してガバナンスをきかせてベストプラクティスも出来上がりそう
- CNPFでも議論されているので期待
- オブザーバビリティの概念は定着してるが、プラクティスやエコシステムが定まっていない
Q&A・クロージング

「複雑なシステムを直感的にグラフィカル化する方法はあるか?」
- 萩野Taijiさん @taiponrock
- Datadogが吸収したCloudCraft
- オブザーバビリティアプローチとしてサービスの依存関係を呼び出してくれる
- 構成図としては見やすい
「オブザーバビリティを社内で浸透させていくためのステップ、誰が主導して巻き込んでいくといいか」
- 松木さん @songmu
- 非常に難しい
- 組織的に意識替えしなくてはならない
- 両面で攻めていく
- 具体的にはアプリケーション側で構造化ログを出していく
- プラットフォームで集約していくか設計してく
- モデルケースになって他のところも導入しやすい
- 自分の責務ではないからやらないのはNG
「監視選定どうしたらいいのか」
- 萩野Taijiさん @taiponrock
- 使いやすいのがベスト
- DatadogはUIがキレイに見やすいのでそういうので選んでもOK
- どれ使ってもいいんじゃない
- 費用と合うのかを選択する基準
- 使いやすいのがベスト
- 松木さん @songmu
- Datadog Logs
- あとから検索しやすい
- ステータスコード400,500も残せる
- あとからトレースもしやすい
- 未来を感じため採用
- 構造化ログをBigQueryで調査しやすい
- あとから素早く調査できるのは便利
- エコシステムを作っていく
- Datadog Logs
告知



DevRelやるよ!Henryエンジニア募集してるよ!次はのイベントはそーだいさん出るよ!(飲み行かなきゃ..!)
まとめ
初心に戻ります📕 pic.twitter.com/Nkeem8RHLW
— adachin👾SRE (@adachin0817) April 28, 2022
先人たちのお話を聞いて、オブザーバビリティの取り組みを社内でどう広めたらいいのかに対してはどこの会社でも苦労しているなと感じました。モニタリングは責務ではないからやらないのではなく、社内エンジニア全員で自分事化をすべきことなので、しっかり計測してくことが大切ですね。また、監視選択をする中でコストを気にしてしまいがちなので、より安価でかつ使いやすいもの選別していきましょう。(SREはここらへんのやり取りが大変)
改めてオブザーバビリティ/モニタリングの重要さを身に沁みるイベントでした!「入門監視」は@songmuさんが書いているので、また読み直したいと思います!オライリーからも「オブザーバビリティ・エンジニアリング」出ているので要チェック!それでは!



0件のコメント