今日は夜こちら参加します!イベントレポートも書くのでよろしくです〜!🤲
オブザーバビリティ最前線 〜 事例LTから学ぶ、オブザーバビリティの成熟度〜 https://t.co/zx3oMGUei7 #o11y_findy
— adachin👾SRE (@adachin0817) May 23, 2023
皆さんお元気ですか!?私はというとオブザーバビリティについてまだまだインプット中なので、今回もFindyの勉強会に参加してきました。それではイベントレポートしていきましょう。今回のスポンサーは「New Relic」さんとなっております。
ちなみにプライベートのサーバー監視も絶賛New Relicに移行中です!(k8sがうまくいかないんだわ..)
無料でできるのスゴイな〜次はアラート設定とDB、k8sもモニタリングしてみようっと。 pic.twitter.com/DImfuBycT7
— adachin👾SRE (@adachin0817) April 23, 2023
※前回のFindyでのイベントは以下参考に!
[2023/02/21][Findy]Datadog社とSongmuさんに聞く。迅速な顧客価値提供のための監視とオブザーバビリティについて参加してきた
イベント概要
https://findy.connpass.com/event/281991/

オープニング・ご挨拶

- Findy
- 山田さん @00_AK1RA
- 気になるテーマは!?
- 監視からオブザーバビリティへが多い
- LTは4名!

『オブザーバビリティの成熟度モデルと 監視からオブザーバビリティへ』New Relic株式会社 (@qryuu)
- New Relic
- 日本支社は2018
- 創業者ルー・サーニー
- Lew Cirne → New Relic アナグラム
- 伊藤 覚宏さん @qryuu
- 昔お世話になりました!
- オブザーバビリティの成熟度
- システムの異常を知るための仕組み:監視
- 監視ができればいいのか!?
- 監視だけではシステムを把握するのは難しい
- 複雑になったシステムをどう管理するのか
- サービスそのままがビジネスの価値になっている
- 利用者が社外でも使うようになった
- ライバル他社も新機能を追加して他社にも負けないように変化が起きる
- 対象が細かく増えていく
- マイクロサービスなど分散していく状況になった
- オンプレミスからIaaSへ
- IaaSからコンテナへ
- システムの変化が当たり前
- 監視設定を完璧にするのが困難
- ユーザー体験も重要
- 解決としてオブザーバビリティ
- 監視からオブザーバビリティ
- オブザーバビリティで何が起こったのかを明らかにして根本原因を探る
- いつもと違う検知を対処
- 成熟度モデル
- ここまでが0や1の受動的対応の部分

『守りから「攻め」の開発へ!New Relicを活用してサービスと共に成長するチームになる』ディップ株式会社(@ramiyon_chan)
- 調査に人為的コストがかかる
- 監視ツールが浸透していない
- エンジニアのパフォーマンスがわからない
- 小森谷良輝さん @ramiyon_chan
- dipカジュアル面談やってるよ!
- New Relic導入の経緯
- ガンガン作れる200人体制の推進
- 多角的なシステム全体の「見える化」
- 監視から「オブザーバビリティへ」
- 困難の数々
- 言語のバージョンが古くてAPMが入らない
- 一部機能がそのままでは使えない
- アラートが次々と上がる
- 便利な点
- APM
- リリース前後の影響調査が容易に
- Service LevelsでSLI/SLOを設定できる
- 分散トレーシング
- スムーズに行かない点を考える
- 便利な点を考える
- 障害検知・調査・対応をみんなでやる
- パフォーマンスチューニングをみんなでやる
- カスタマイズを考える
- 開発チームのパフォーマンス
- Four Keysの計測
- パフォーマンスのデータを結びつける
- 1年でだいぶ形になった
- 今後
- 計測を豊かにして、データから企画立案へ
- 開発チームのパフォーマンスをKPIにできないか
- 他プロダクトとの連携・展開

『問題解決の促進 -New Relicの導入から全社活用までの道のり-』弥生株式会社 牛尾哲朗
- 牛尾 哲朗さん
- 弥生株式会社
- 二郎私も好き!
- オブザーバビリティに力を入れている
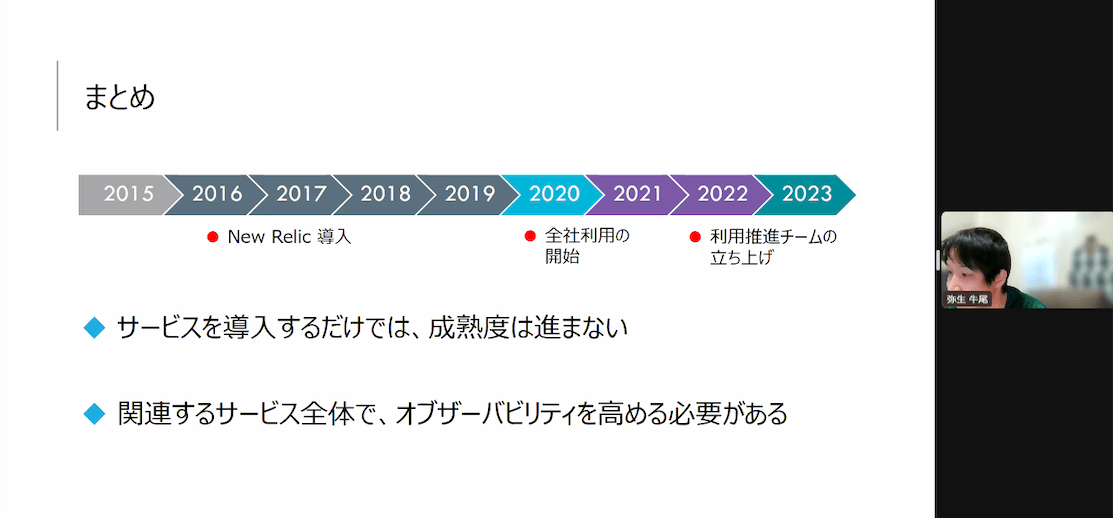
- 2015年以前
- Zabbix Mackerel
- 2016年に一部New Relicを導入
- APMとBrowserのみ
- 0:計測を始める
- YAYOI AMART CONNECTから計測を始める
- APIの呼び出しについてはTraceできていなかった
- 2020年から全体サービスに導入開始
- いつどこの処理が遅かったのかチームで横断的に取り組めるようになった
- InfrastructureやSYnthetics、Alertsも
- 2022年 利用促進チームの立ち上げ
- New Relic TFC
- サービスを導入するだけでは、成熟度は進まない
- 関連するサービス全体で、オブザーバビリティを高める必要がある
『サービスレベル管理 (SLM) とは? – 計測すべき指標と活用について-』New Relic株式会社 (@qryuu)
- SREの役割
- サービスの健全性
- 評価可能な信頼性=SLO(サービスレベル目標)
- 開発が今何に注力しているのかがターゲット
- SLA(サービスレベルアグリーメント)
- SLO(サービスレベル目標)
- SLI(サービスレベル指標)
- SLIの定義
- サービスを利用するユーザが期待しているようなことを指標とする
- Good Event(良いイベント)
- Valid Event(総イベント)
- 応答の品質
- 目標値は高くするとみんな見なくなってしまう
- 高すぎる目標は高コスト
- SLIの計測
- エラーバジェットの活用
- 信頼性回復の判断ができる
- 実際に見直しして適宜変更していく
- SREを実践する上での根幹
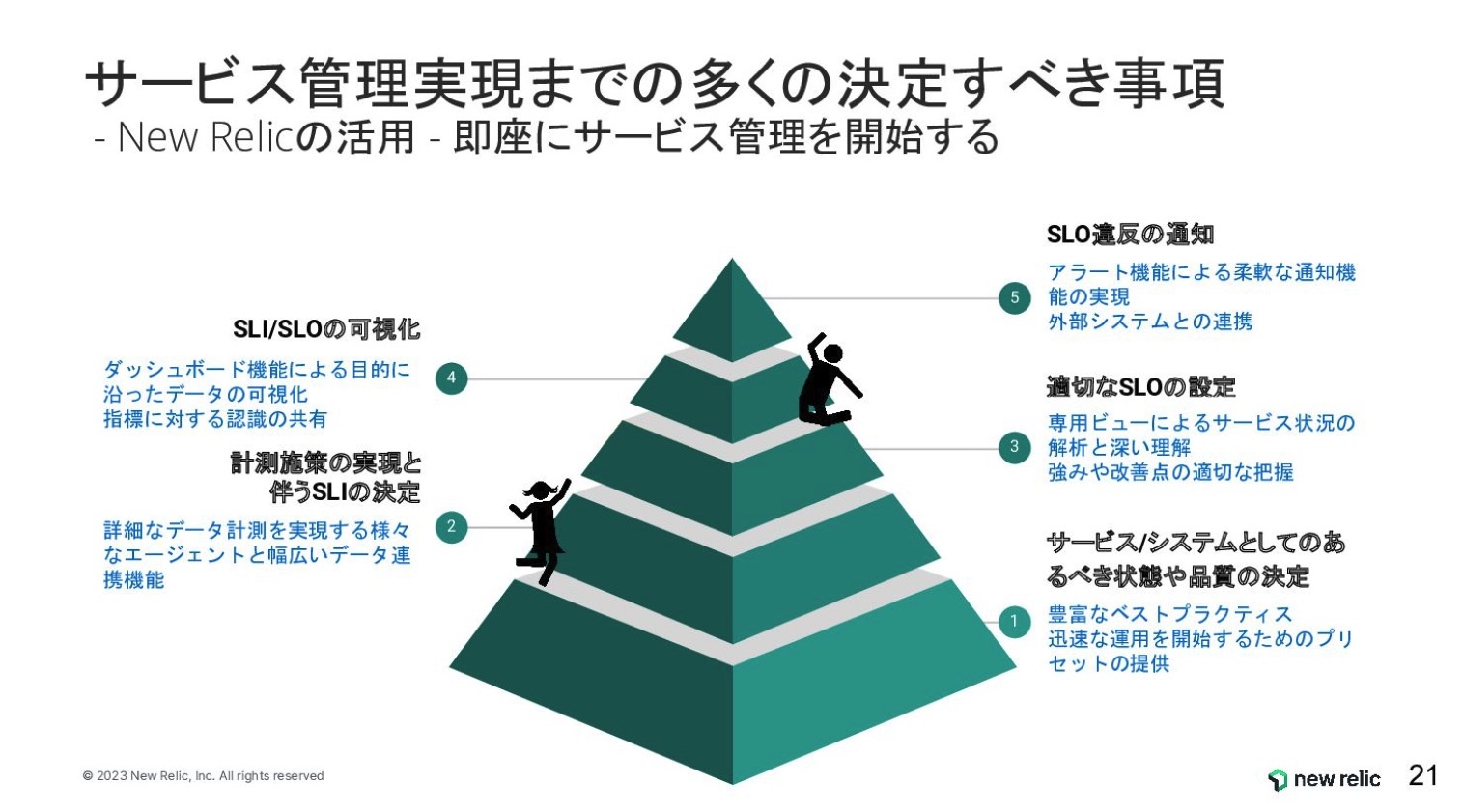
- 悩むべき事項は山積みが現実
- New Relicでは簡単に自動的にSLOを定義できる
- 個別のサービスを品質状況を可視化
- サービスレベルをもとにした3つのアラートを簡単設定
『全世界のユーザー体験の改善にNew Relic Mobileをどのように活用したか』株式会社MIXI(@isaoshimizu)
- 清水 勲さーーーん!@isaoshimizu
- MIXI SRE
- 海外ユーザ増加中
- 海外ユーザは快適に使えているのだろうか
- いろんな国や地域に行って調査するのはコストが高い、効率が悪い
- ユーザーの端末内のアプリの通信状況を知りたい
- New Relic Mobileによってユーザー端末内のアプリの状況を把握できる
- iOS/Android向けのSDKを利用してアプリに実装
- APIのレスポンスタイムを国ごとに計測
- アメリカは日本の2倍
- ヨーロッパは日本の3倍
- 数字が取れたのはポイント
- 差があるのが分かった
- SLIの計測ができた
- どうやって差を縮められるか
- できるだけ日本のレスポンスタイムに近づけたい
- 東京リージョンに加えてヨーロッパリージョンを追加
- マルチリージョン化施策
- EKSクラスタをus-east-1
- Aurora Global Databaseをus-east-1
- ユーザーから近いALBにルーティングさせる
- 効果の高いAPIを優先して対応
- 効果は?
- 2倍程度まで早くすることができた
- 数字で語れるようにしよう
- 効果測定ができないとかけたコストの説明ができない
- APIが遅くなっても体感が良いとは限らない
- ここらへんの内容は以下エンジニアブログを参考に!
https://team-blog.mitene.us/mitene-infra-multi-region-614717f0162d

『New Relic Service LevelsとバーンレートアラートをCDK for Terraformで設定してSLOモニタリングをセルフサービス化した話』 株式会社ニューズピックス(@integrated1453)
- 安藤 裕紀さん @integrated1453
- ニューズピックス SRE
- SLOモニタリングの課題
- 顧客体験からSLI/SLOを決め、SLOを基準にサイトの信頼性を維持していく
- ひとまずSLIの現状をもとに教科書的なSLOを設定
- レイテンシーが問題ということしかわからない
- SLOをモニタリングして、SREが信頼性の問題になる?
- SLO違反したら全開発チームの作業を止めることはできない
- 門番から支持者/パートナーへ
- 意味のある情報を提供
- 開発チームがSLOのモニタリングと改善を自走できるまでサポートする
- SLO違反からエスカレーションまでの調査
- 手動でのエスカレーションを自動化したい
- クリティカルユーザージャーニーに立ち返る
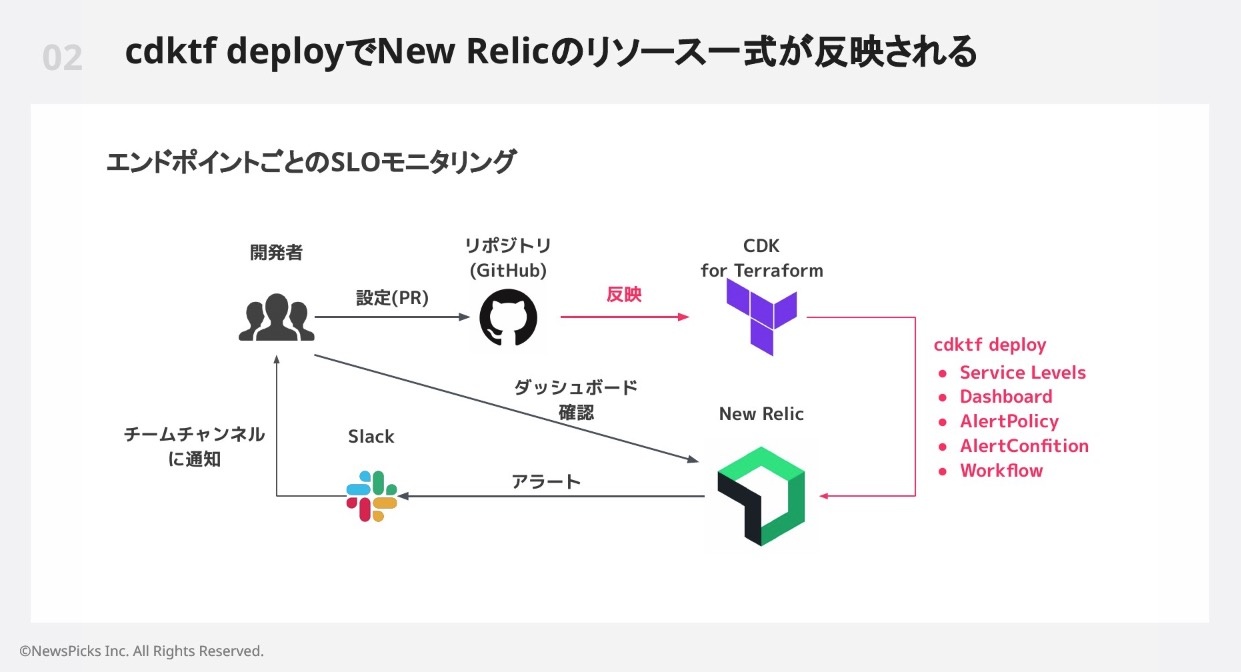
- 開発者はSLOを簡単に設定
- Slackチャンネルに通知を受け取る
- SREはNRQLやダッシュボードのIac化
- バーンレートアラートのしきい値
- CDK for TerraformでNew Relicのリソース一式が反映される
- 導入効果
- config追加でダッシュボードとアラートが作成できる
- SLOモニタリングやってみません?がしやすくなった
- 開発チームでもNew Relicを使いこなす
- ハードルが下がる
- TypeScript、CDK for Terraformでメンテできる
- 今後
- ユーザー割合ベースの可用性・レイテンシーを確認する
- PRをマージ後手動でdeploy、dev環境で気楽にCI/CDできるようにする

『DevSecOpsへの展開 – 全てのチームの能力を最大限に引き出す』New Relic株式会社 (@qryuu)
- 脆弱性が公開された!何をすればいいのか
- ネットで調べる
- 影響度の確認
- アプリケーション修正
- 工数がかかる
- New Relic Vulnerability Management
- サードパーティと連携ができる
- フルサイクルで全システムから脆弱性トリアージが可能
- 脆弱性対応にまつわる問題意識
- モダン開発
- 大企業セキュリティ
- 開発統括
- ゼロデイ攻撃対応

Q&A/クロージング

- 振り返りはどのようにしているか
- レトロスペクティブで指標をみている
- New Relic以外のツール選択どのように決めたか
- 開発メンバーが使いたいということから決めた
- GitHub Actionsでどの項目を転送しているのか
- 有料顧客から項目を考えた。使っているデバイスを見ている
- エンドユーザーからの承諾は必要か?
- 利用契約との兼ね合いが必要でなんとも言えない
- 改善活動の中で苦戦は?
- マルチリージョンの対応がきつい
- 試行錯誤の繰り返し
- New Relicでこんな機能があればいいはあるか
- ダッシュボードで変数が使えるが、制約が多いのでラフに使いたい

まとめ

各社の取り組みや現時点でのオブザーバビリティについての全体のステップと、どのフェーズにいるかが判断できました。また、色々と活かせそうなので、改善できたらアウトプットできればと思います!まずは個人のサーバーモニタリングをNew Relicに早く移行しなきゃ..!
New Relic実践入門届きやした!!爆速で読み切ろう📖 pic.twitter.com/uDl2mLtMde
— adachin👾SRE (@adachin0817) April 26, 2023



0件のコメント